







As great as OpenZFS is at being a general-purpose filesystem, there’s one task it’s even better suited to: serving as the storage back end for virtual machines.
The features we already know and love in OpenZFS–per-block checksumming, instantaneous snapshots, rapid asynchronous replication, and extensive tuning for special workloads–are exactly what the VM architect ordered.
Whether for general infrastructure, or highly specialized workloads, an administrator can achieve great results just slapping VMs down on a completely untuned OpenZFS pool. In moderately-sized and larger production environments, however, we’ll want to lean on some of that fine-grained tuning we referenced a moment ago–and even small business and homelabbers who don’t need additional performance can benefit from our guidance on best practice.
Let’s dig in!
Hardware Guidelines
If you’re building smaller scale infrastructure, you likely won’t need to performance-tune your storage at all. The defaults are sufficient for light and frequently even medium-duty use, on most workloads.
For those who do need to tune for additional performance, OpenZFS offers more flexibility than we’ve got space to cover here–so we’ll stick to discussing the three most important factors: hardware, topology, and recordsize.
Do I Need Fancy Drives?
For the best results, a physical drive which houses VM images should not only be “fast”–it should be predictably fast, and reliably fast even when hit with sustained, long-running workloads.
This, unfortunately, means consumer and even “prosumer” M.2 SSDs are typically terrible choices for VM hosting. Although these drives appear blisteringly fast when hit with very simple workloads (like dd) for short periods (typically under 30 seconds, and in some cases under 5 seconds), they aren’t designed for the rigors of VM hosting. Most of this class of drive relies on a very limited embedded SLC cache to accelerate performance. Then, it falls off “the write cliff” when hit with a large enough volume of writes to fill that cache. Similarly, consumer M.2 drives tend to have insufficient heat dissipation–so they’ve got another “cliff” to fall off when the drive thermally throttles itself. Additionally, drives without power-loss protection increase the risk of data loss, and tend to perform poorly in workloads that use a lot of synchronous writes.
By contrast, SATA consumer SSDs still suffer from narrow write caches and that resulting cliff–but they rarely if ever encounter thermal events. And good “prosumer” SATA SSDs are designed to perform well even after their SLC cache is filled–which is why that Samsung Pro costs more than that Samsung EVO, and it’s why that Pro is worth more than the EVO as well!
Best Recommendation For Long-Running Workloads
If the workload calls for it, we highly recommend “enterprise” or “datacenter” grade SSDs. These are, by far, your best choice for virtualization storage. In addition to being designed to perform well with extremely long-running heavy workloads, these drives typically offer some form of hardware QoS (Quality of Service, which minimizes latency spikes, keeping performance reliable instead of bursty and laggy), PLP (power loss protection, which allows the SSD to accelerate synchronous writes without risk of data loss, since the DRAM cache is technically no longer volatile), and double or even quadruple the write endurance ratings of lesser drives.
Drives For Demanding Workloads
For more demanding workloads, the best answer is hot-swappable U.3 NVMe drives. With newer models offering huge IOPS & throughput figures and with capacities reaching parity with spinning disks, they provide an easy answer when performance is a hard requirement.
If you take note of nothing else, please take note of that bit about write endurance. When SSDs were new, people liked to repeat the mantra that they would wear out faster than HDDs ad nauseam. After a few years, the same people began instead repeating the mantra that SSDs would effectively never wear out–which isn’t any truer than the first mantra was.
Drive Limitations for VM Storage
Lastly, we do not recommend small SSDs for VM storage. Remember, write endurance is in part a function of the total drive size available–it’s measured in DWPD, or Drive Writes Per Day, so a 1TB SSD has double the raw write endurance of the 512GB variant of the same model of drive.
This all gets too complex to give a single “correct” answer about what drive to pick for what application, but if you’d like a few rules of thumb:
- Don’t buy SSDs smaller than 1TB
- Don’t underestimate the performance impact of PLP and/or QoS
- Include write endurance in your project planning and future-proofing
We find that a 1TB consumer SSD in a typical consumer desktop role begins showing signs of significant performance degradation within 3 to 5 years of use. In the same role and with the same workload, a 2TB consumer SSD would still be performing well after 6 to 10 years–as would a 1TB datacenter-grade SSD.
Be warned, that doesn’t necessarily mean you can expect to get the same 3 to 5 years out of a 1TB consumer SSD that’s hosting VMs! If the VMs are lightly loaded and only used by a handful of people, they may follow desktop use patterns–but in a more heavily loaded server, we’ve seen even 4TB prosumer SSDs lose half their initial performance in less than a year’s time!
If you expect to fill up your current storage and discard the drives quite rapidly, it might not make sense to buy more expensive drives with higher longevity–but if you expect to get five or ten years’ use out of the same drives, you will likely find that the higher-priced datacenter drives are actually a thriftier purchase than the consumer stuff.
Do I Need a Discrete SATA/SAS Storage Controller?
Once again, most systems will be perfectly fine with motherboard SATA–but if you need extreme performance, you’ll need a higher-grade, discrete SATA/SAS controller.
This is because SATA controllers, whether onboard or discrete, almost never offer more than a single PCIe lane on their back end. SAS controllers, on the other hand, typically are delivered in PCIe x4 form, with some higher-end controllers offering PCIe x8!
A single PCIe 3.x lane offers full-duplex throughput of roughly 2GB/sec. However, that’s split into ~1GB/sec up and ~1GB/sec down–the lane cannot upload data at 2GB/sec or download it at 2GB/sec.
Meanwhile, a single SATA port offers a theoretical maximum throughput of 6Gbps–which works out to around 750MiB/sec. The commonly-repeated myth that SATA controllers share 6Gbps between all ports is just that, a myth–but it’s an understandable myth, when you realize the PCIe bottleneck behind the controller is about the same size!
It’s also important to remember that just because your CPU and motherboard support a higher version of PCI Express with a higher per-lane bandwidth, your controller might not. For example, an LSI 9300-8i is only going to have ~4GB/sec throughput whether it’s plugged into a PCIe 3.0 board or a PCIe 6.0 board, because the controller itself only supports PCIe 3.
Do I Need Gobs of RAM?
Unfortunately, the answer here is pretty much “yes.” Although OpenZFS doesn’t require anywhere near as much RAM as oft-repeated urban myths may claim, VM hosting is a particularly RAM-hungry workload, and will definitely benefit from the highest storage cache hit-rate you can manage.
This doesn’t necessarily mean huge amounts of RAM–but we do recommend leaving the OpenZFS default of “up to half the physical RAM may be used for ARC” intact, and you’ll want to keep around 2GiB of RAM available for the host operating system itself.
So, if you’re deploying KVM on a server with 32GiB of RAM, we’d recommend planning around OpenZFS taking the first 12-16GiB, the host OS taking another 2GiB, and the 14GiB remaining being available for allocation to the actual VMs.
If you’re bound and determined to do more with less, you can decrease the value of zfs_arc_max to your liking–and if you really know what you’re doing, it’s possible you’ve got a workload that will benefit from tuning arc_max smaller (or larger).
But for the most part, we do not recommend changing this value without considering the consequences.
Do I Need A Honking Big CPU?
For the most part, no–OpenZFS is not particularly CPU-hungry. A blisteringly fast CPU will have some impact on storage performance, but it’s not usually a significant bottleneck–we’ve set up perfectly functional KVM hosts on the older AMD Kabini processors for edge deployments, these embedded systems retailed for well under $50, but were able to provide the compute where it was needed.
However, if you want to run a lot of VMs, you may rapidly become core constrained. The ideal configuration for a VM host allocates one physical CPU core to each virtual core allocated to a VM; this allows all VMs to operate at full speed without inducing unnecessary and expensive context switching to share multiple virtual threads on a single physical thread.
It’s entirely possible to run core-oversubscribed, and in fact the majority of VM hosts we encounter are running at least a little oversubscribed–but not too much. The more heavily you use those virtual cores, and the more they outnumber the real physical cores that need to do the work, the more frequent and expensive that context switching gets.
Finally, although this isn’t really VM specific, you need very fast CPUs if you plan to serve a 10Gbps or faster network. Most network transport methods bind on a single CPU thread per flow–which can easily bottleneck a network operation on a “10Gbps” LAN to 3Gbps or less. The faster your CPU, the less pressing this bottleneck becomes.
Performance Tuning
We’re going to be honest up front here–there’s a lot to cover in regard to tuning OpenZFS for maximum performance on any workload, very much including virtual machine hosting. Once again, the defaults will suit most people most of the time, and we simply don’t have the space to cover it all here! If you are looking for expert advice, check out Klara’s ZFS Performance Analysis solutions.
We’d also like to reiterate that many smaller deployments and homelabs will find performance tuning entirely unnecessary–we’ve even seen plenty of small businesses running well on the defaults. But for those who do need more performance, there’s plenty more to unlock.
Now, let’s get into three of the most important criteria for those who do tune their systems: back end type, pool topology, and recordsize.
Back End Type
Most hypervisors offer support for offering a VM a raw storage device directly, as well as for emulating raw storage devices using flat files of one type or another. Serendipitously, OpenZFS allows you to create raw storage devices–called ZVOLs–directly. Obvious win, right?
Unfortunately, not in every case. Although using ZVOLs as VM storage back ends is extremely prevalent–this is very nearly the only way one can set up a VM using the Proxmox GUI, for example–the performance can be impacted by other layers of the operating system.
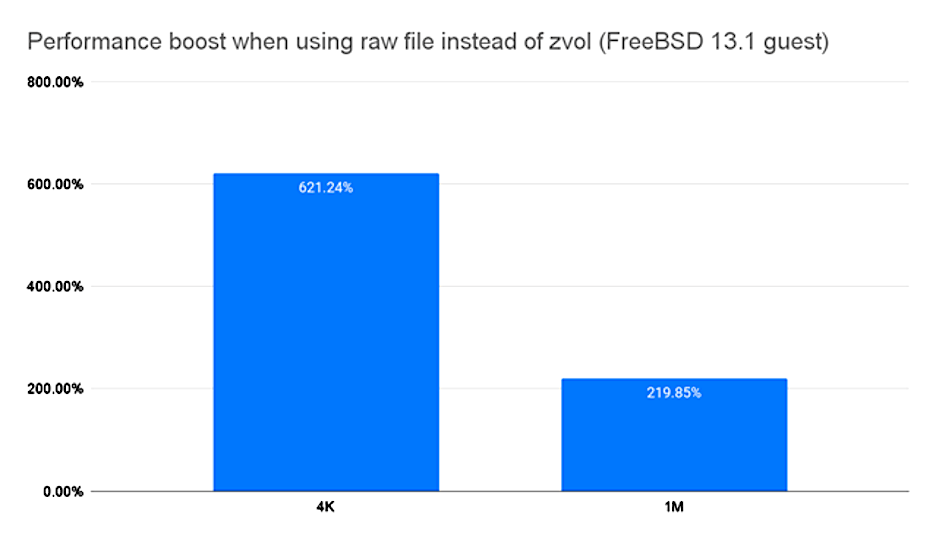
In the above chart, we see the performance difference when a FreeBSD 13 VM is migrated from a ZVOL back end to a raw file back end. It is not a subtle difference–the raw file is more than twice as fast as the ZVOL at easy 1MiB random I/O workloads, and over six times faster on more challenging 4K I/O!
Raw files also offer a performance boost above .qcow2 files, but the difference is not as stark. An empty .qcow2 file will typically perform at about half the speed of a raw file, but a fully-allocated .qcow2 file performs essentially the same.
Pool Topology
This one is incredibly important for performance–if you’re serious about performance, you want mirror vdevs, full stop. No, a big wide RAIDz won’t perform better because it uses more drives–in fact, it will typically perform significantly worse, often slighty worse than a single drive would. That’s not unique to RAIDz–the same thing is true of striped conventional RAID as well!
Essentially, the relationship here is simple: pool performance does not scale with number of drives, it scales with number of vdevs.
This means that for an eight-bay system, the highest performing topology is a pool of eight individual single-disk vdevs… which we do not and cannot recommend, since it’s completely non-redundant and with 8x the drive failure rate of a single disk!
The next highest performing topology in an 8 bay system is four two-wide mirror vdevs, followed by two four-wide RAIDz2 vdevs (or two three-wide RAIDz1, if you’ve got a better use for the other two bays). Any of the above will outperform a single disk–but a single six-wide Z2 will not reliably outperform a single disk.
If you’d like to read much, much more on the topic of topology and performance, we recommend this author’s 2020 Ars Technica article, ZFS vs RAID: Eight Ironwolf Disks, Two Filesystems, One Winner.
OpenZFS Recordsize
Although OpenZFS offers literally tens of tunable knobs that can greatly impact performance under various specific workloads, it’s easy to pick which single tunable to cover in an article with limited space: recordsize.
The OpenZFS recordsize parameter controls the maximum block size in a dataset. For VM hosting, this may generally be considered a single, static value–because while ZFS will avoid wasting space and dynamic allocate each file in a dataset, any file larger than a single block will be written in a number of blocks, each of recordsize size.
Since our VMs will necessarily need pretty large files, those files will be using the exact value of recordsize specified–and that size should, generally speaking, match the I/O operation size of the workload the VM encounters.
OpenZFS itself currently defaults to recordsize=128K, or 128KiB blocks. This isn’t a terrible value for VM hosting, but it’s rarely a great one, either. Generally speaking, we recommend recordsize=64K for general-purpose VMs–because both ext4 and NTFS do the majority of their I/O in 64KiB extents and 64KiB clusters, respectively.
If you’re using .qcow2 back end storage, you need to be aware that it has its own matching tunable, called cluster_size. Qcow2 cluster_size defaults to 64KiB–so for most general-purpose use cases, you don’t need to do anything with cluster_size itself; simply adjust recordsize to match.
But what if you’ve got a more specialized workload? Databases generally work best with smaller recordsize, matching their internal page size–16KiB in the case of MySQL, or 8KiB in the case of PostgreSQL… but then again, double the page size can sometimes increase efficiency in the database dramatically, if the database is packed chock-full of columns that write two pages’ worth of data to every row.
With databases–or other applications that do small blocksize random I/O inside much larger individual files–it’s important not to set recordsize too large, because recordsize=128K on a PostgreSQL database means needing to read sixteen database pages from storage for every one page the DB actually needs!
Finally, what about VMs that share great big chunky files, like all those Linux ISOs you keep on your Plex server? (Ahem.) You want to go in the other direction, for these–recordsize=1M, or potentially even larger.
We go for very large blocksize in file sharing applications because these large files are read “sequentially” in large chunks and streamed across the network–so there’s no significant risk of read amplification, and minimizing the total number of blocks means minimizing the amount of fragmentation in the files, the seeks necessary to read or write them, and the total discrete IOPS needed to read or write them as well.
Conclusion
For everything from the largest enterprise and academic deployments to the most humble home lab users, OpenZFS will provide unmatched reliability, ease of administration, and the flexibility to grow and tune as your needs scale.
If you’ve got a heavy-duty workload that needs more tuning than you’ve got the time, energy, or expertise to provide, reach out to the experts at Klara for development, solutions, and support!