







The most common category of ZFS questions is “How should I set up my pool?” Sometimes the question ends, “...using the drives I already have,” and sometimes it ends with, “...and how many drives should I buy?” Either way, today’s article can help you make sense of your options.
In some cases, the questioner wants to know how to make the best use of the disks they already have; in others, they want to know how many (and what kind of) disks to buy. Either way, understanding the building blocks a ZFS pool is made of is crucial to answering the question.
It’s probably best to look at this question from the top down: rather than beginning with “disks” and working our way up to “pool,” let’s do it the other way around.
What Is a ZFS vdev?
A ZFS vdev (virtual device) is a group of disks arranged in a specific topology that determines a pool’s performance, redundancy, and fault tolerance.
A zpool is a collection of vdevs
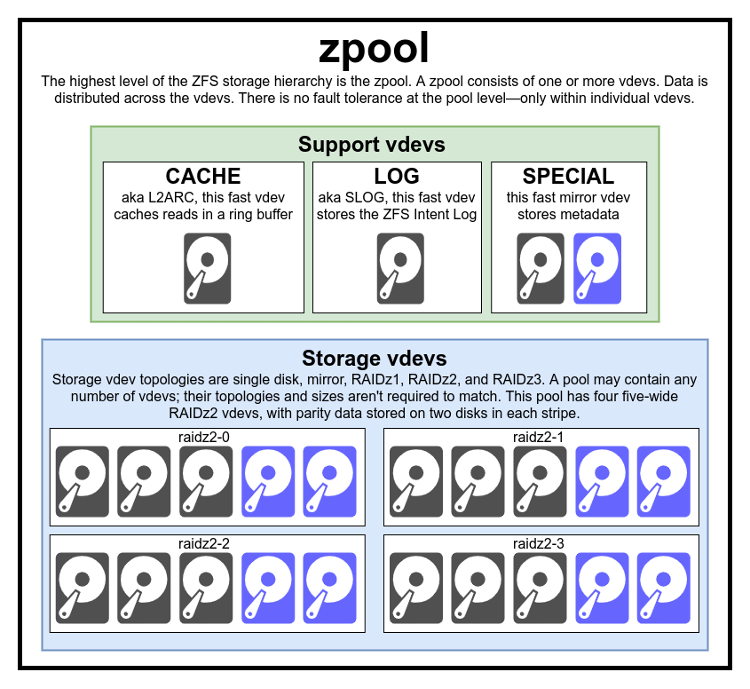
The above diagram shows us a pool which uses four RAIDz2 vdevs, and one of each of the currently supported types of support vdev.
Beginning at the very top, the zpool is the top-level ZFS structure. In terms of structure, a zpool is a collection of one or more storage vdevs and zero or more support vdevs. In terms of utility, a zpool is a storage object which may be further divided into datasets (which look like folders) and zvols (which look like simple block/character devices, such as raw disks).
Note that a zpool does not directly contain actual disks (or other block/character devices, such as sparse files)! That’s the job of the next object down, the vdev. Short for virtual device, each vdev—whether support or storage—is a collection of block or character devices (for the most part, disks or SSDs) arranged in a particular topology.
How Do ZFS vdev Types Affect Performance and Redundancy?
Different ZFS vdev topologies make different tradeoffs between storage efficiency, performance, rebuild times, and fault tolerance.
Storage vdevs
A storage vdev may be of topology single, mirror, RAIDz1/2/3, or DRAID. The first three topologies are relatively simple—but DRAID is its own beast, which we’ll cover in its own section later.
Single
Single: the simplest type of vdev contains a single disk. There is almost no fault tolerance here (metadata blocks are stored in duplicate, but that won’t protect you from a full drive failure). This is the absolute fastest vdev type for a given number of disks, but you’d better have your backups in order!
Mirror
Mirror: this simple vdev type is the fastest fault-tolerant type. Mirrors are most commonly seen in two-wide configurations, but larger numbers are also supported. In a mirror vdev, all member devices have full copies of all the data written to that vdev. Reads can go at up to n times faster than a single disk, where n is the number of drives in the vdev, but writes are constrained to slightly slower than a single disk, no matter how many disks are in the vdev.
RAIDz1
RAIDz1: this striped parity vdev resembles the classic RAID5: the data is striped across all disks in the vdev, with one disk per row reserved for parity. In classic RAID5, the parity is “staggered” so that it doesn’t always fall upon the same disk, which improves performance while degraded and while rebuilding. RAIDz1 relies instead on its dynamic stripe width to mix things up: unlike classic RAID5, RAIDz1 can write small amounts of data in narrow stripes. So, a metadata block, which is a single sector wide, will be stored as a single data block and single parity block, even on a much wider RAIDz1 vdev—which not only saves space and increases performance, but also effectively distributes parity across all disks in the vdev, rather than always saving it to the same disk on each stripe written.
RAIDz2
RAIDz2: the second (and most commonly used) of ZFS’ three striped parity vdev topologies works just like RAIDz1, but with dual parity rather than single parity. In this case, a metadata block would be written to three drives, not two: one drive gets the original data, and the other two get parity blocks. Where RAIDz1 vdevs can lose a single drive without catastrophic failure, RAIDz2 vdevs can lose two.
RAIDz3
RAIDz3: this final striped parity topology uses triple parity, meaning it can survive three drive losses without catastrophic failure—and also meaning that metadata and other small blocks are written to four drives in total (one data and three parity).
Support vdevs
Now that we know the storage vdev topologies, let’s talk about vdev classes. (“Vdev class” and “support vdev” are not official ZFS terminology, but they offer a useful way to categorize and understand how ZFS manages storage!)
Currently implemented support vdev types are LOG, CACHE, SPECIAL, and SPARE:
LOG
LOG: Let’s start talking about the LOG by clearing up a common misconception: LOG vdevs are not a write cache or buffer. In normal operation, ZFS saves sync writes to disk twice: once, immediately, to the ZFS Intent Log and then, at some point later, to main storage. In the absence of a LOG vdev, both of these writes will be to the main storage vdevs.
Counterintuitively, these double writes improve sync write throughput, mostly by decreasing latency through the use of pre-allocated ZIL blocks, which avoid spending time finding a location to place the data, and reduce fragmentation and therefore seek latency. A LOG vdev is simply a place to keep the ZIL which isn’t main storage: no more, no less. Typically, the LOG vdev is a very low latency device, so syncing data to it will be significantly faster than main storage, this is why the LOG vdev class exists. Writes to the LOG are never read from again unless there is a system or kernel crash, which is why the LOG should not be thought of as a “write buffer!”
Although a fast LOG vdev can massively accelerate sync-heavy workloads, it will have no effect whatsoever on workloads without many sync writes... and the majority of workloads, even server workloads, don’t include much in the way of sync writes. Examples of workloads that are sync-heavy include NFS exports, databases, and VM images.
In early versions of ZFS, losing a LOG vdev meant losing the entire pool. In modern ZFS, the loss of a LOG vdev doesn’t endanger the pool or its data; the only thing at risk if a LOG fails is the dirty data inside it which has not yet been committed to disk.
A LOG may use either single or mirror (any size) topologies; it cannot use RAIDz or DRAID. You may have as many LOG vdevs as you like, if you have so many sync writes that you’d prefer to distribute the load across multiple LOGs!
CACHE
CACHE: in one sense, the CACHE vdev (aka L2ARC) is simpler to understand: it really is just a read buffer. Unfortunately, it’s not actually an ARC—Adaptive Replacement Cache. L2ARC is a simple LILO ring buffer, fed not from blocks which have expired from ARC, but from blocks which may expire soon.
The CACHE vdev has a pretty limiting write throttle on it to keep it from burning through SSDs like a cutting torch through toilet paper, which also means the odds of it having a particular block you’ve already read available are lower than you might expect. Combine that with the extremely high hit ratios in the main ARC, and CACHE vdevs just don’t generally get many hits for most workloads. The CACHE vdev will never have a high hit ratio, as once there is a hit, that block is moved back to the main ARC.
Losing a CACHE vdev does not adversely impact the pool, aside from losing whatever acceleration might have been gained from the CACHE itself.
The only supported CACHE topology is single-disk. Since a CACHE never stores the only copy of data, and its loss will not impact the pool, there’s no reason to support anything but the absolute fastest and simplest topology. (Note: you can absolutely have more than one CACHE vdev if you like, to distribute the load across more than one disk.)
SPECIAL
SPECIAL: the SPECIAL vdev is the newest support class, introduced to offset the disadvantages of DRAID vdevs (which we will cover later). When you attach a SPECIAL to a pool, all future metadata writes to that pool will land on the SPECIAL, not on main storage.
Optionally, the SPECIAL may also be configured to store small data blocks. For example, with special_small_blocks=4K, individual files 4KiB or smaller will be stored entirely on the SPECIAL; with special_small_blocks=64K, files 64KiB or smaller are stored entirely on the SPECIAL.
The special_small_blocks tunable may be set on a per-dataset basis. You cannot opt out of metadata blocks being stored to the SPECIAL: if you have one (or more) it (or they) will get all your metadata writes, period.
Losing any SPECIAL vdev, like losing any storage vdev, loses the entire pool along with it. For this reason, the SPECIAL must be a fault-tolerant topology—and it needs to be just as fault-tolerant as your storage vdevs. So, a pool with RAIDz3 storage needs a quadruple mirrored SPECIAL—your storage vdev can survive three drive failures, so your SPECIAL must also be able to survive three drive failures.
Much like the LOG vdev, you may have as many SPECIAL vdevs as you like, if you need to distribute the load across more drives. Unlike the LOG, however, losing any SPECIAL irrevocably loses the rest of the pool along with it!
SPARE
SPARE: the SPARE vdev does nothing at all during normal operation, but sits ready to be automatically resilvered into any vdev which throws a disk. Obviously, a SPARE must be at least the size of a failed disk in order to automatically replace that disk!
If your pool has only a single storage vdev, it doesn’t need SPAREs. The utility of a SPARE is that it can service any vdev in the pool which becomes degraded. In a single-vdev pool, it makes far more sense to adjust parity than to implement SPAREs—for example, in a twelve-bay system, an eleven-wide RAIDz3 vdev will perform significantly better than a ten-wide RAIDz2 vdev plus a SPARE.
The major indicator that you might need SPARE vdevs is storage vdev count, not storage disk count. If you’ve got six or more vdevs, you should almost certainly maintain one or more SPAREs—and it doesn’t much matter if those six vdevs are two-disk mirrors (twelve drives total) or ten-wide RAIDz2 (sixty drives total); either way, you really want the reduced vulnerability window a SPARE offers when one of your vdevs becomes degraded!
What Is dRAID in ZFS?
dRAID is a distributed RAID topology for large ZFS storage systems that combines parity protection with distributed spare capacity to accelerate resilvering after drive failures.
ZFS' newest vdev type: DRAID
We’ve teased DRAID above a few times, but it’s very difficult to explain properly without understanding what came before it—so, now that we’ve gone over standard vdev topologies and support vdev types (especially the SPARE), let’s talk about DRAID.
This topology was designed for systems with 60 or more drives, and replaces a traditional group of storage and SPARE vdevs with a single, enormous vdev that incorporates both RAIDz and SPARE functionality.
Let’s say you’ve got exactly sixty disks, and you want to rock them in a DRAID. Your first step is deciding your stripe width and parity level... which, unlike RAIDz, are not strictly constrained by the number of drives you have available.
Before DRAID, you might have decided those sixty disks should be nine six-wide RAIDz2 vdevs plus six SPARE vdevs. As soon as you decided the width and parity level of your vdevs, the number of vdevs became fixed: essentially, you can’t put more than ten six-wide vdevs onto sixty total disks.
DRAID, however, offers more flexibility: while you certainly can choose a DRAID2:4:4 (each stripe has 2 parity blocks and four data blocks, and the DRAID as a whole offers 4 drives worth of distributed spare capacity), you might also choose a DRAID3:4:4. Obviously, three parity and four data blocks per stripe doesn’t add up to an even divisor of your total sixty drives... but it doesn’t need to, because DRAID will cheerfully “wrap” a stripe as and if necessary to make it fit the matrix of drives you have.
There is a devil in those details: making a DRAID stripe width which doesn’t evenly divide into the number of disks you have will probably produce a performance penalty. But when you’ve got 60 disks or more, that sort of performance issue tends to melt away: your bottleneck on a sixty-drive system tends to be the drive controllers themselves, not the individual drives.
In a DRAID configuration, rather than a specific disk mapping to a certain stripe within one particular RAIDz, each of the members of the DRAID vdev is distributed across all 60 disks in the vdev. When a disk fails, rather than having lost an entire stripe, instead the loss is 1/60th of each of the 60 members.

If a drive fails in our DRAID vdev, the block pieces which belonged to the failed drive are reconstructed from parity, and resilvered onto the distributed spare capacity inside the DRAID. This resilvering happens much faster than a traditional resilver onto a SPARE vdev. For comparison, consider our previous example, a six nine-wide RAIDZ2s with six spares. When a disk fails, we’d be reading from the remaining eight disks and writing to a single spare. Whereas with DRAID, because the major bottleneck of a traditional resilver—write speed—is now distributed over all fifty-nine remaining drives, not just a single drive! We end up reading from fifty-nine drives and writing to fifty-nine drives, which will obviously complete much quicker than the eight and one from a traditional RAIDz.
Unfortunately, in order to reclaim that used distributed spare capacity, the DRAID vdev’s operator must still perform a traditional resilvering of a new disk into the DRAID, and that resilver will be just as slow as any traditional resilver. However, there is a vulnerability window for the first resilvering (because the DRAID is down one parity level) and there is no vulnerability window for the second (since the missing parity level has been restored by making use of distributed spare capacity).
DRAID vdevs do come with downsides, though—the largest one being that they lose traditional RAIDz vdevs’ ability to store data in dynamic stripe widths. If you have a DRAID2:4:4, every stripe must be six disks wide (four data plus two parity), even if that stripe only stores a single 4KiB metadata block.
This is where the SPECIAL vdev comes in—while a SPECIAL might be nice to have on a traditional pool, it’s a near-necessity on a pool with a wide DRAID vdev. Putting metadata (and, optionally, other very narrow blocks) on the SPECIAL means not having to waste inordinate amounts of both disk space and performance on wastefully storing them in full-width stripes!
| By the way, have you ever wondered why ZFS reports less available space than expected? Our recent article, ZFS Space Accounting Explained, details it clearly and breaks it down step by step.
Conclusion
If your head is spinning from all the options ZFS makes available to you, we can help with a few rules of thumb:
- CACHE (aka L2ARC) vdevs are much less useful than commonly supposed. Typically, any other pool performance enhancement will outperform L2ARC—so use your budget, in both $$$ and open drive bays, wisely!
- LOG (aka SLOG) vdevs are outstanding performance accelerators for sync-heavy workloads... but odds are very good you don’t have a sync-heavy workload in the first place. If you aren’t running NFS exports, databases, or VMs (especially VMs which offer databases or NFS exports), a LOG probably won’t do you any good.
- SPECIAL vdevs sound pretty sweet, and they’re a near-necessity for anyone rocking DRAID storage. But they’re a bit risky, since losing a SPECIAL loses the entire pool, and we’ve found that many workloads on smallish rust pools in good health tend not to benefit noticeably. Be cautious here.
- If you’ve got noticeably fewer than 60 drives, DRAID is probably not a good fit for you.
- Topology makes an enormous difference in performance. Twelve disks in a single RAIDz1 vdev will usually perform worse than a single disk. Twelve disks split up into six two-wide mirror vdevs, on the other hand, will usually perform many times better than a single disk.
- If you’ve got three or more storage vdevs, one or more SPAREs is a very good idea. If you’ve got six or more storage vdevs, one or more SPAREs is pretty much a functional requirement!
- For any given number of disks, narrower stripes and higher vdev count will outperform wider stripes and lower vdev count for the vast majority of workloads. Yes, this is even noticeable on all-SSD pools!
For more specific recommendations, reach out to us to arrange a personalized consultation—one of our storage experts can analyze your actual workload and design the right ZFS system to service it!







