







Inline deduplication–the ability to store identical copies of the same file or block without actually taking up more storage space–is an exciting OpenZFS feature. Unfortunately, that feature has historically imposed such severe performance problems that experts advise against using it.
However, there’s a brand-new revision of OpenZFS dedup dubbed “fast dedup” which directly addresses those performance issues. Before we put it to the test, let’s talk briefly about how dedup works.
How Does ZFS Dedup Work?
The essential concept of inline dedup is that every time OpenZFS writes a block to disk, it first creates a hash, then checks that hash against a pool-wide dedup table (DDT).
If the block’s hash matches a hash already stored in the DDT, then ZFS doesn’t need to actually write the “new” block at all. It simply adds an extra reference to the block which produced the matching hash that already existed in the DDT. Obviously, this saves the drive space which would otherwise have been occupied by the block in question–less obviously, it may also increase performance, since the drives themselves are the slowest part of nearly any storage stack.
If the block’s hash is unique, then ZFS writes the block as normal, and adds a new entry to the DDT.
Unfortunately, the need to compare the hash of every block to be written with the hash of every block that’s already been written is something of a Herculean labor. The larger the DDT gets, the longer this comparison can take.
What’s New in Fast Dedup?
The short answer is, unfortunately, “too much to cover here.” Fast Dedup operates similarly to the legacy dedup–but it offers faster lookups, more control over the dedup process, and safer operation to boot.
We’re here today to test the code, not document it. You can find a list of the latest changes and features in the Fast Dedup Review Guide.
The documentation above will mostly be of interest to developers and storage architects. From a typical OpenZFS admin’s perspective, increased performance is the only visible change.
Hands-On Testing OpenZFS Fast Dedup
Now that we know the basics of what dedup is and how it works, let’s get our hands dirty. First of all, we need to talk about how we’ll test. Then, we’ll compare the new OpenZFS fast dedup code to legacy dedup (and no dedup at all).
Our test system is a humble i5-6400 with 16GiB of RAM, and a single Kingston DC600M 1.92TB SSD plugged into a motherboard SATA controller. The relatively anemic CPU gives the newer code plenty of opportunity to show off its speed, and the relatively low amount of RAM helps us expose dedup’s weaknesses with smaller test datasets.
Many of our tests will use fio, the Flexible I/O tester, to read and write streams of pseudo-random data. The data fio creates is configured to be 30% compressible and 30% dedupable.
As of FreeBSD 14.1 and OpenZFS 2.2.4, compression is on and set to LZ4 by default. Therefore, we’re testing with compression enabled, and we’re giving it something to compress. This introduces a little more variability in our testing but keeps us closer to real-world conditions.
Mixed Read/Write Tests: Throughput
Let’s start with a generic test that models a generic storage workload. In this test, we throw eight fio processes at our pool, each of which hits a 12GiB file with a mixed read/write random access workload.
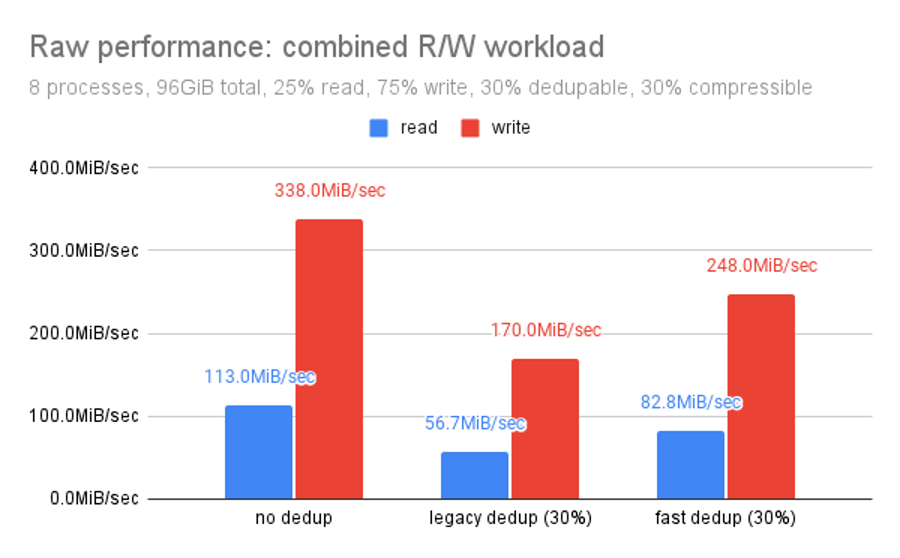
In this test, our dataset has recordsize=16K, but fio is reading and writing data in 128KiB blocks. We set it up this way for a few reasons: first, many of dedup’s performance issues scale rapidly with DDT size–and going with a 16KiB recordsize means we’ll have 8 times as many DDT entries as the same data would require in a dataset with the default recordsize of 128K.
Although our ZFS block size is 16KiB, we’re asking fio to move data 128KiB at a time. This large block size mismatch isn’t how we’d normally test storage. Yet, it’s necessary here for fio’s “dedupability” to apply at the ZFS level.
We can see immediately that no dedup outperforms fast dedup which in turn outperforms legacy dedup. Let’s take another look at the same data. This time, focusing on the relationship of each dedup routine to un-deduped storage on the same hardware:
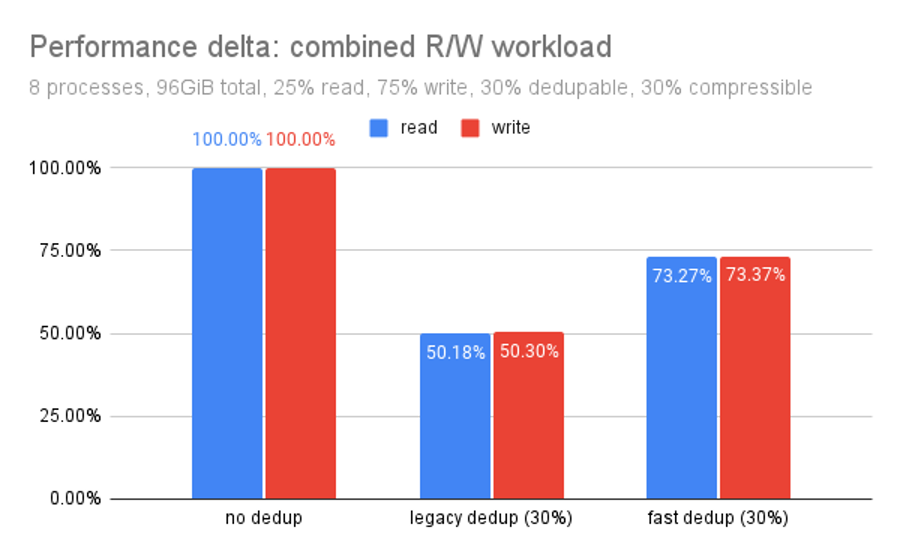
Again, this is the exact same data we already saw: it’s just organized a bit differently. With 96GiB of 30% dedupable data, we’re looking at what amounts to a 50% performance penalty for using legacy dedup, versus a 25% performance penalty for using the newer OpenZFS fast dedup. Not bad!
You might be wondering “why are the bars for read and write near-identical in this chart?” We’ll go over the answer in more detail later, but the short version: we’re saturating the pool IOPS.
The workload is a fixed 25%/75% split between reads and writes, with as many mixed operations issued as our pool can commit. Any advantage in reads results in more IOPS available to fulfill write requests, and vice versa.
Exploring Read/Write Dynamics in OpenZFS Fast Dedup
Later, we’ll look at read-only and write-only workloads directly. This will help us see where dedup performance shines and falters, in ways the graphs alone cannot show. However, the data behind these graphs more accurately models a typical system workload, making it more applicable to real-world scenarios.
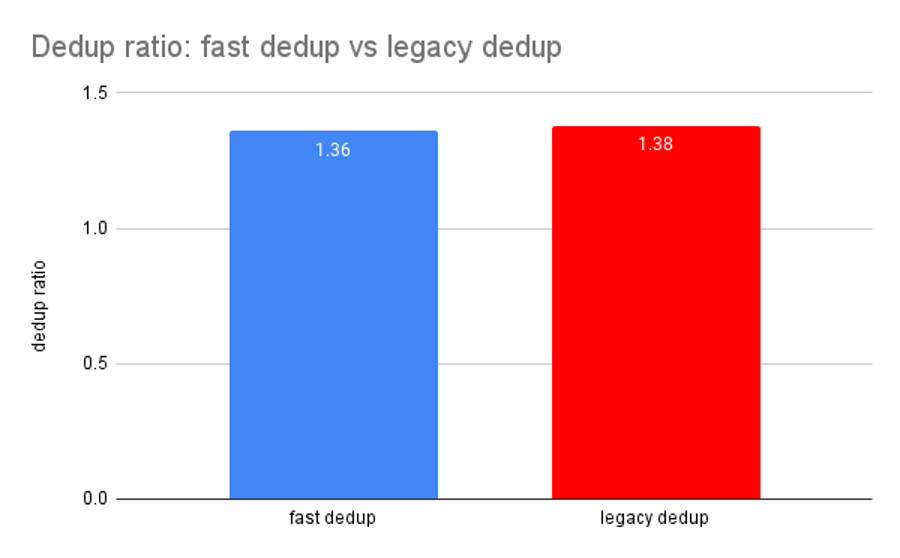
Essentially, legacy and fast dedup produce identical results when it comes to dedup ratio. You can see a very small difference between the two values in the chart above, but they’re well below the noise floor.
The 0.02x delta between OpenZFS fast dedup and legacy dedup seen above is not consistent between runs, and does not always exhibit the same direction. We may safely assume it is an artifact of minor differences in the pseudorandom data streams generated by fio, not in each codebase’s ability to detect duplicate blocks.
Mixed Read/Write Tests: Latency
Although throughput is the most commonly (and easily) measured storage metric, it’s rarely the most important. Many applications–including databases, desktop user interfaces, and games–depend far more heavily on latency. Latency is the time to complete a task, rather than the number of tasks which can be completed in a given time.
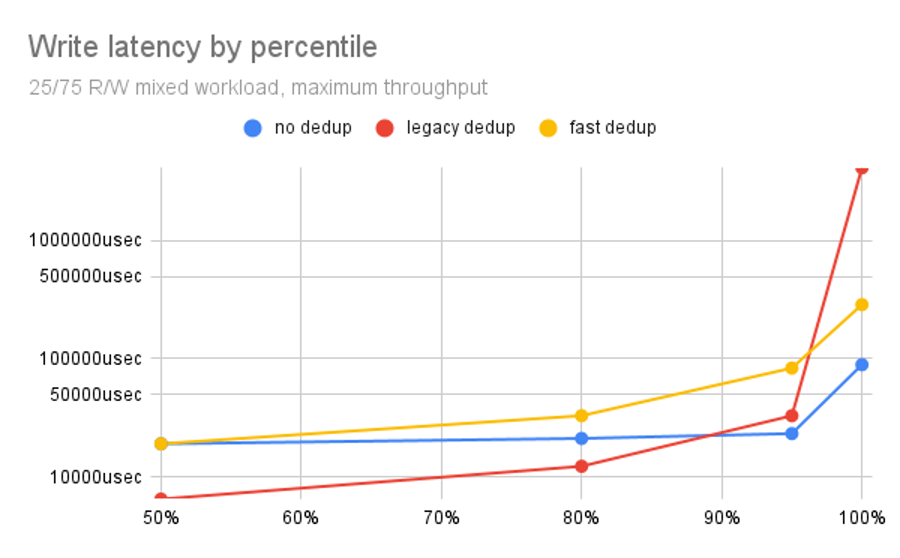
In this write latency chart, we see something curious: legacy dedup not only outperforms fast dedup, for much of the chart it also outperforms no dedup! What’s the catch? The first catch, of course, is just how badly it underperforms either toward the right side of the chart.
The X axis on our latency charts refers to percentiles from the latency results of all the individual operations performed in our 5 minute test runs. So, all the way to the left of the chart, at 50%, we’re looking at median latency.
Moving to the right, our next data point is at the 80th percentile, followed by the 95th percentile, and finally the maximum (worst-case) latency experienced during the entire 5 minute run. Realizing that the Y axis is log scale, we see that things get much worse after the 95th percentile.
You might think that the first 95% of the chart outweighs the last 5%. However, that’s not the case. The performance delta favoring legacy dedup on the left side of the chart is relatively small, where the delta penalizing it in the last 5% is enormous.
The next thing to understand is that we’re examining individual operations at the block level. Most storage interactions involve the need to read multiple blocks, not just one.
If you ask for 100 blocks, and only one of them is approaching that massive maximum latency on the right edge of the graph, the latency from that one worst-case block ruins the aggregate latency for the entire operation.
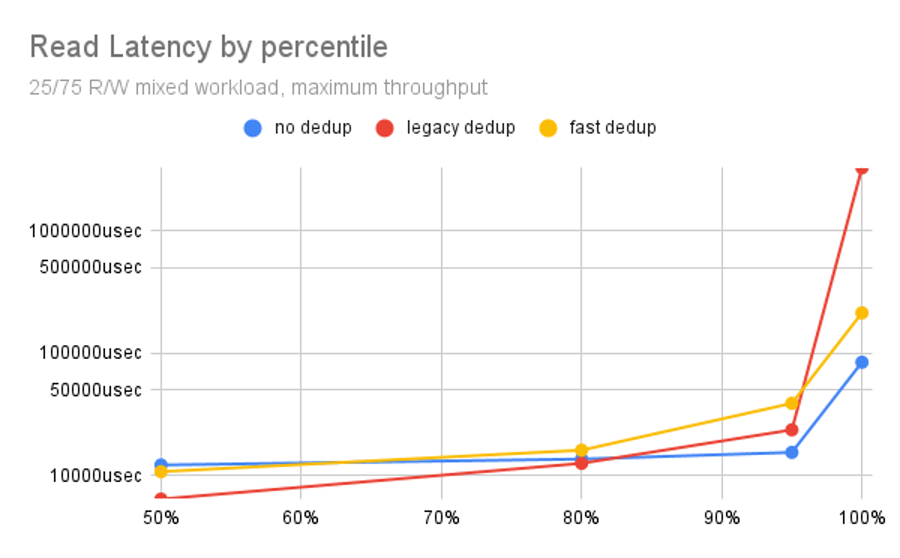
When we examine read latency, we see a different shape but roughly the same relationship: for the first 80 percentiles, legacy dedup is faster than no dedup. By the 95th percentile, legacy dedup has slowed down enough to be passed by no dedup. Further, the 100th (worst) percentile, legacy dedup is multiple orders of magnitude slower than either fast dedup or no dedup.
Once again, the massive negative disparity at the right of the chart outweighs the mild positive disparity seen on the left side. Being half an order of magnitude faster for the first 80% of results does not outweigh being several orders of magnitude slower in the worst case!
Latency Under Long-Term Use
There’s another issue with these latency charts, though: they chart the results of a fully-saturated workload. Most storage systems do not operate fully saturated most of the time! What happens if we rate-limit our tests to roughly half the pool’s maximum throughput, more closely modeling typical long-term use?
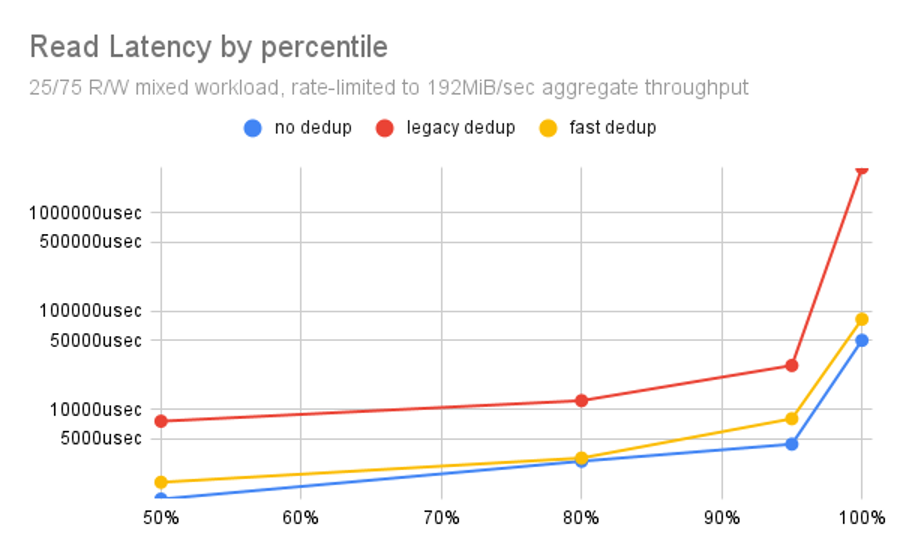
Moving back to read latency, this time we examine the spectrum of individual operation results while the throughput of our workload is sharply limited. Under these more-realistic, less-extreme conditions, we can see the real issues with legacy dedup code.
On a pool that stays fully IOPS-saturated for more than 5 minutes straight, legacy dedup didn’t look so bad. Yet, on a pool with a more reasonable workload, we see legacy dedup imposing an order of magnitude (10x) penalty or more, all the way across the chart.
By contrast, the new code–OpenZFS fast dedup–stays very nearly even with no dedup whatsoever, remaining within an order of magnitude even at the maximum worst-case value.
What this tells us is that reads aren’t likely to feel slower with fast dedup enabled–while reads with legacy dedup enabled nearly always felt slower, and for good reason.
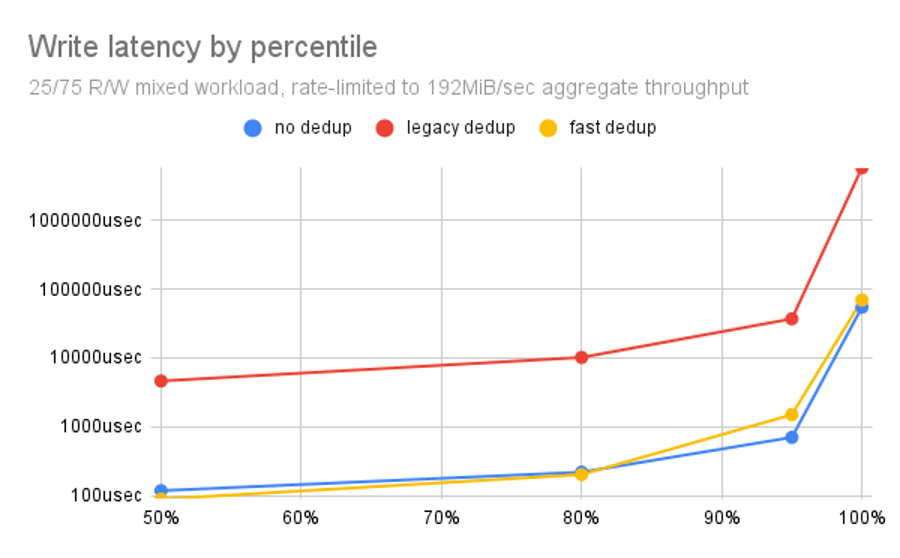
Legacy dedup’s write latency issues are even worse than its read latency issues.
Here, we see essentially no difference between OpenZFS no dedup and OpenZFS fast dedup, while legacy dedup is nearly two orders of magnitude (100x) slower than either. This is consistent across the entire spectrum of point results.
If you were looking for a single chart that clearly says “fast dedup rules, legacy dedup drools,” this is the one.
How Dedup Affects Reads and Writes Individually
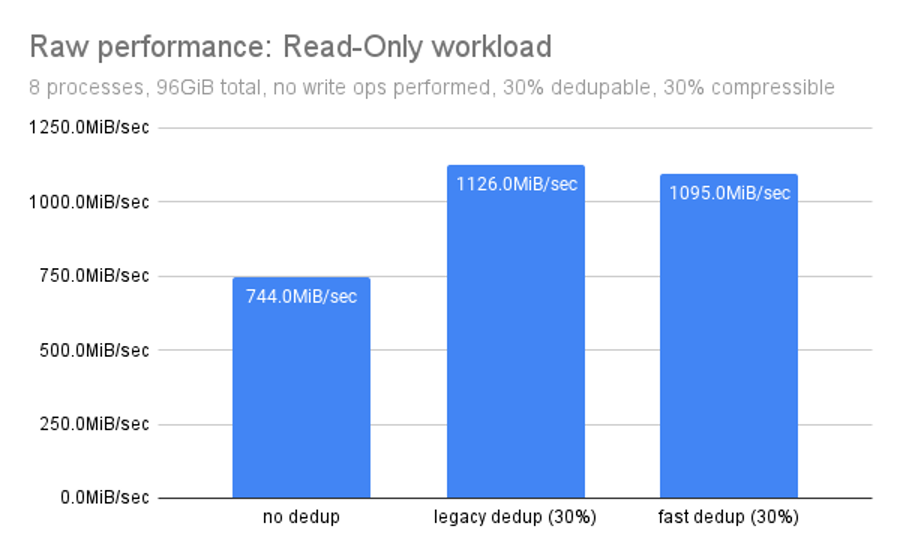
This chart displays results for almost the same random-access tests that we ran earlier–but this time, on an all-read workload. It allows us to see the impact of dedup on reads themselves, without worrying about improvements or regressions in write performance indirectly impacting the reads (by leaving more or fewer IOPS available after servicing the writes).
With this working set, dedup is an obvious win in terms of read throughput: whether we’re using OpenZFS fast dedup or legacy, we see a roughly 50% performance improvement vs using no dedup at all.
Why do these results look so different from the earlier ones? Our earlier tests measured how dedup performs on mixed workloads with both read and write components. Those tests helped give us realistic real-world expectations.
This strict read-only test (and the strict write-only test we’ll be looking at next) helps explain why dedup can be slow, and where the pain comes from.
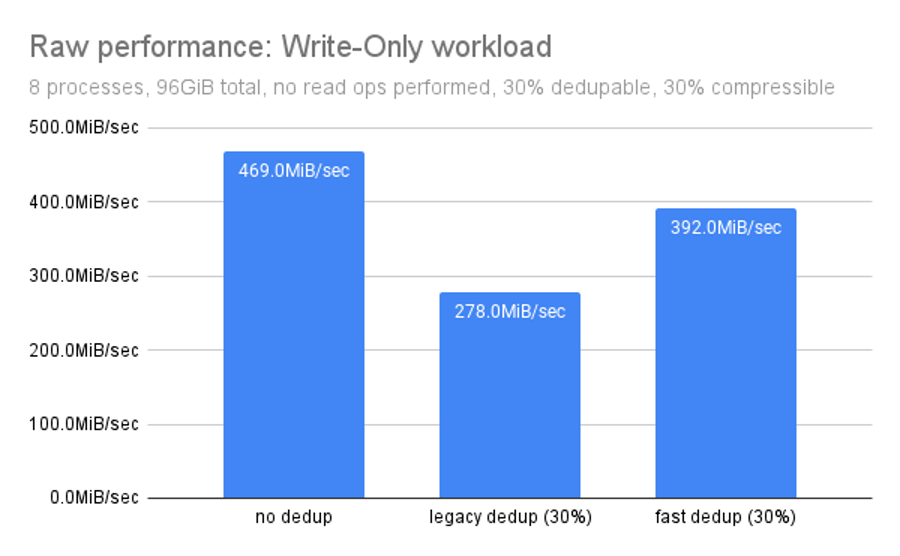
Dedup pain almost always lies in the writes, not the reads. Each time the system receives a potentially-dedupable write, the hash of that block must be compared with every hash in the DDT before it can be committed. This, unavoidably, slows writes down.
This is also where OpenZFS fast dedup shines–its writes are a whopping 41% faster than legacy dedup’s, although they’re still slower than no dedup at all. The system is performing additional work after all.
Bursty, high-duplication workloads
One of the big issues with deduplication is that most people drastically overestimate the amount of actual duplicate data on their systems. We’ve been testing with 30% dedupable data, so far. That’s enough to make sure that we can see the potentially positive performance impacts of dedup, along with the unquestionable negatives.
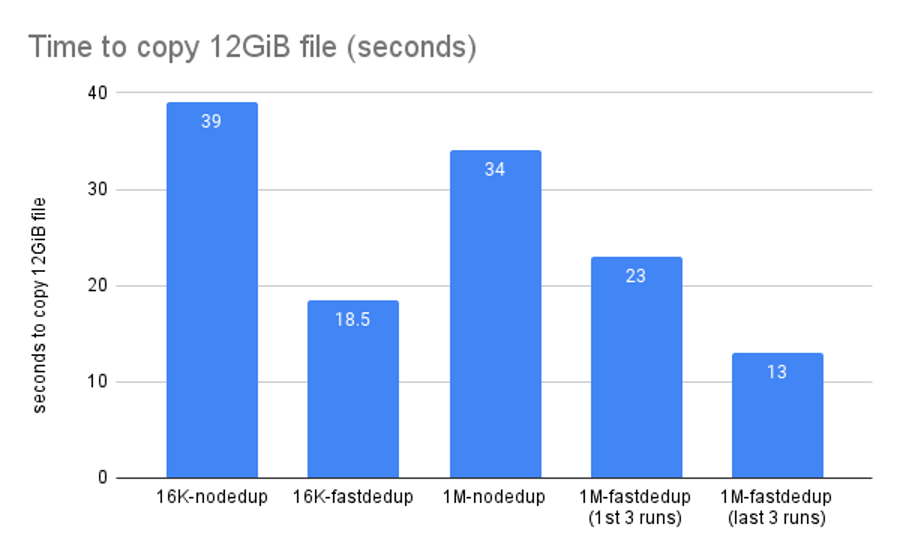
However, we hear people proposing unusual workloads that might be especially dedup-suitable all the time. What happens if we model one of those?
In the chart above, we use the cp command to duplicate one of fio’s 12GiB testfiles. You might think such a copy would be near-instantaneous, since the entire operation is 100% dedupable–but reality is less impressive.
OpenZFS filesystem cloning is near-instantaneous. When applicable, it can reduce that 12GiB copy in milliseconds, not seconds. But ZFS clones work on entire snapshots, not files, and have dependency issues that can be frustrating.
Evaluating Deduplication for Specialized Workloads
A few weeks ago, we talked about the new OpenZFS Block Cloning feature, which does accelerate this specific workload, making identical copies of files. Since we were testing on a FreeBSD 14.1 base operating system, we also needed to disable BRT. With Block Relocation enabled, the same file copy operations completed in roughly 4 seconds each. This still isn’t anywhere near as fast as cloning, of course. Unfortunately, BRT-deduplicated copies also don’t stay deduplicated on the other side of a zfs send.
When BRT is not enabled, cp will read the original file and write it as new blocks, and only then can ZFS see that the blocks are identical to existing blocks and avoid writing those new blocks. Since the 12 GiB file is too big to entirely fit in the cache, some of those reads are going to have to come from disk and be slow.
18.5 seconds feels like a very long time to sit and stare at a copy operation–but 18.5 seconds is much better than 39 seconds, and not every workload is amenable to ZFS cloning.
In these tests, we also examine the impact of moving from recordsize=16K to recordsize=1M. That impact seems small here, because this is a sequential workload on a server with no other work going on in the background. On a more heavily loaded server, it would be much more significant.
We also see an unusual effect with increased recordsize. Each test was run a half-dozen times, to check for inconsistency or error. The no-dedup and recordsize=16K dedup runs were extremely consistent across all six runs, but the 1M dedup run took a while to “settle”--the first three runs were actually slower than the 16K runs, with the last three runs “settling” to a final, higher performance state.
We suspect this has a lot to do with the higher compute impact and generally increased fiddliness of calculating DDT checksums on 1M blocks rather than 16K blocks. Unlike compression, which tends to increase the larger the blocks get, dedup ratios tend to decrease with increased block size, since any change at any position in the block ruins its dedupability.
If you have this relatively unusual use case–the need to frequently make brute-force copies of large volumes of data–dedup can helpful. It improves both performance and storage efficiency. However, you may want to experiment directly with various recordsizes before committing to one in production.
“Wishful Thinking” Workloads
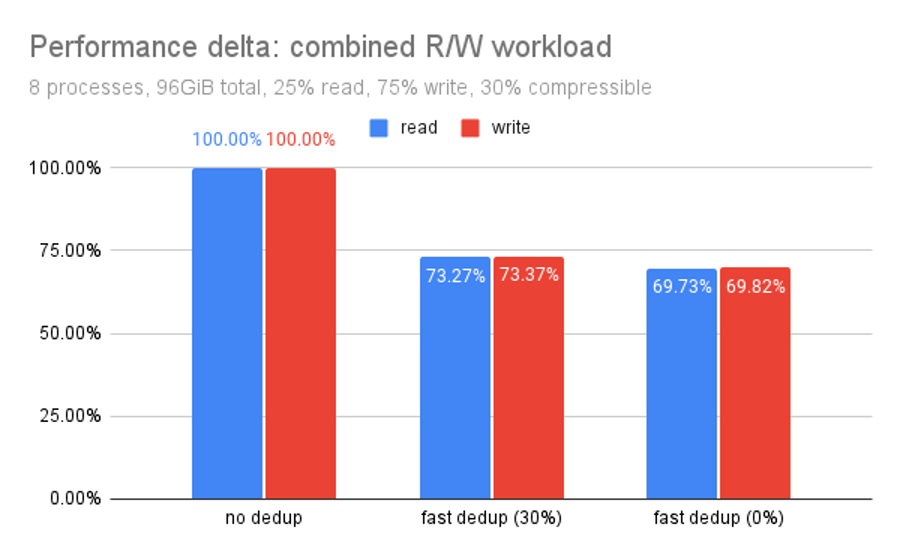
So far, we’ve only looked at the performance impact of deduplication on very dedup-friendly workloads. Experience has taught us that very few workloads are really this dedup-friendly.
This chart helps us examine the worst-case scenario for dedup: read and write operations on a pool with no duplicate blocks whatsoever. With no duplicate blocks at all, our performance penalty only increased by about three percent.
Dedup still isn’t a good idea without lots of duplicate data–but at least the penalties don’t get much worse if you misjudge how much duplicate data you have.
Further Room for Improvement
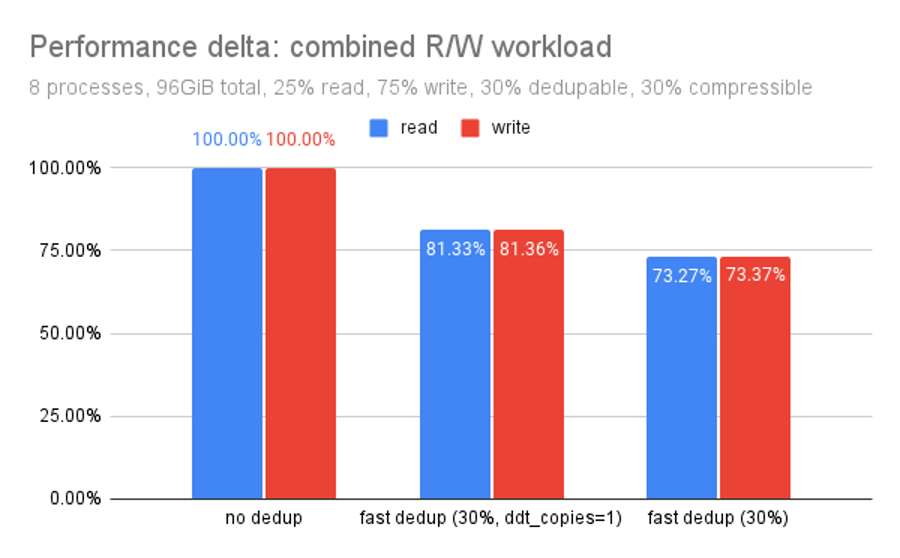
By default, each DDT block (like most OpenZFS metadata) is stored in triplicate, with two ditto blocks for each data block written. This is nice for stability, but it does have a measurable impact on performance, as we can see in the chart above. By storing a single copy of each DDT block, rather than storing it in triplicate, we get an 11% performance boost.
This belt-and-suspenders approach used to make a lot of sense, because a corrupt block in a legacy DDT can make an entire pool unmountable. But OpenZFS fast dedup is much safer.
If a block in the fast dedup DDT becomes corrupt, it becomes effectively immutable. Even so, the pool will still mount, and the data the corrupt block referenced will still read just fine.
If losing the ditto blocks still makes you nervous, remember that the DDT also benefits from vdev-level redundancy. A DDT stored on RAIDz or mirror vdevs is just as redundant as the rest of the data on those vdevs! Meaning if you were mirroring your DDT, we were actually storing 6 copies and would now only store 2.
Real-World Benefits of OpenZFS Fast Dedup
OpenZFS’s new fast dedup still isn’t something we’d recommend for typical general-purpose use cases–but let’s take another look at its potential upsides in the use cases it does fit:
- Significantly decreases latency on large, bursty duplicate writes
- Conserves write IOPS when duplicate blocks are discovered
- Conserves ARC space by only requiring one copy of a duplicate block to be cached
- May significantly increase read performance due to more available IOPS and more ARC headroom
- Conserves write endurance on SSD media
Where Should I Avoid Using Fast Dedup?
Very few real-world workloads have as much duplicate data as the workloads we played with today. Without large numbers of duplicate blocks, enabling dedup still doesn’t make sense.
Fileservers rarely have much duplicate data on them in the first place–which frequently surprises their administrators, who often find those sloppy and unnecessary extra copies infuriating. But by volume, it tends to be less than 5% of what’s on the server.
Surprisingly, mailservers are also poor candidates for dedup. A 100KiB message delivered to jim@ and john@ will be impossible to deduplicate. The first block is different because the names are different. Additionally, since the names are a different length, the rest of the blocks are also different, because they begin on different boundaries.
If you host VMs and deploy from golden images, you might have a very nice dedup ratio–but only briefly. Once-identical virtual machines diverge from one another surprisingly quickly–we’ve seen a server go from 5x dedup ratio to 1.15x in just a couple of months.
The performance problems with dedup–even fast dedup (to a far lesser degree)–scale upward with the size of the DDT. Massive pools will see larger performance penalties than the ones we demonstrated today. The larger the pool you plan to build, the more important preliminary testing and validation will be.
Where Should I Consider Using Fast Dedup?
Specialty workloads which involve routinely dumping additional copies of large volumes of data are an obvious potential fit. This might mean frequently “seeding” multiple VMs from a single golden image, CI/CD systems, deploying datasets for AI training, or deploying the AI models themselves. Essentially, if you have one of these workloads, you already know it–you don’t need us to describe it for you.
If you don’t have a specialty workload, the next application that leaps to mind may surprise you–database servers. Most database workloads involve a very large amount of duplicate data. The DB engine is generally kind enough to keep all that duplicate data in the same positions in identically-sized pages.
How much duplicate data will depend on the database application itself–for example, a personnel management application will probably have more duplicate data than a WordPress blog does.
But if you have enough duplicate writes, enabling OpenZFS fast dedup may actually accelerate your workload–and also conserve write endurance on the underlying solid state drives, as well.
If you’ve got a workload that you’ve determined benefits greatly from dedup, message us on social media! We’d love to hear your story.
Wrapping Up on ZFS Fast Dedup
OpenZFS’s fast dedup replaces the legacy functionality with a far more performant version, offering a viable solution for workloads where space savings is a critical priority. With these performance and manageability improvements, fast dedup can serve organizations looking to optimize data storage without the severe trade-offs of legacy dedup.
For those looking to fine-tune their ZFS setup, Klara's ZFS Performance Audit provides a comprehensive analysis of your storage performance. A successful audit entails a holistic assessment of hardware, software, and workload dynamics. It involves analyzing system profiling, workload patterns, latency measurements, throughput evaluations, and resource utilization. With Klara’s solution, you can ensure that your ZFS deployment is running at peak efficiency, ready to handle your data demands effectively.