







Morning Overview
This is part of our article series published as "OpenZFS in Depth". Subscribe to our article series to find out more about the secrets of OpenZFS
As with most other conferences in the last six months, this year’s OpenZFS Developer’s Summit was a bit different than usual. Held via Zoom to accommodate for 2020’s new normal in terms of social engagements, the conference featured a mix of talks delivered live via webinars, and breakout sessions held as regular meetings. This helped recapture some of the “hallway track” that would be lost in an online conference.
Each breakout room was led by a prominent developer from one of the different platforms supported by OpenZFS, and one was reserved for the previous speaker to continue to answer questions. The webinar style also allowed the audience to submit written questions to be answered at the end.
A Bit of Conference History
The first OpenZFS developer’s summit was held in San Francisco in November of 2013, with 30 developers attending. By 2016, the summit had grown to over 100 developers and added a second day hackathon where new features and enhancements are prototyped.
The devsummit serves the important purpose of facilitating the sharing of information between the various platform teams that maintain OpenZFS on the different operating systems. Now that the OpenZFS repository contains both Linux and FreeBSD support, this has become even more important.
State of OpenZFS by Matt Ahrens
The conference opened with Matt Ahrens, the leader of the OpenZFS project, presenting the “State of OpenZFS”, which included the major milestone of the common repo containing both Linux and FreeBSD code, and the new yearly major release model starting with OpenZFS 2.0 this fall.
Then OpenZFS 3.0 was briefly covered, including the potential for the MacOS port to get merged into the common repo. Lastly, a gentle nudge from Matt and us at Klara - there is a monthly OpenZFS Leadership meeting, which is live streamed, and open to everyone. So if you have stakes in ZFS or would just like to know more, we definitely encourage you to follow!
ZFS Caching: How Big Is the ARC? by George Wilson
Continuing a trend started a few years back, there was a talk that focused on the inner workings of one of the subsystems of ZFS. Last year it was the ZIO Pipeline, and this year the ARC (Adaptive Replacement Cache). The goal of these talks is to expose more developers to the details of these subsystems or algorithms, to grow the knowledge base of the developer community, and create more subject matter experts.
George Wilson’s talk, “How big is the ARC”, highlighted differences between the platforms, as he adjusted to his switch from illumos to Linux, and how the interaction between the ARC and the kernel memory management system changed. As he highlighted in his talk, his mental model did not match what was happening, and lead to incorrect assumptions.
Persistent L2ARC by George Amanakis
The second level cache has been a major feature of ZFS for most of its history, but until recently, its contents were wiped out after a reboot. The L2ARC works by reducing the copy of a block in the primary cache (ARC) to just a header with a pointer to the location within the L2ARC where that block is cached. After a reboot, there was no way to reconstruct those header blocks. With the Persistent L2ARC feature, a small log is written to the L2ARC device containing the required data to recreate the ARC headers.
One of these log blocks can contain pointers to 1022 data blocks, and they are written each time they are filled. After a reboot, these log blocks can be read back to repopulate the ARC. After some experimentation, it was determined that having 2 chains of these log blocks allowed the data to be loaded back in much more quickly. The device header for each L2ARC devices contains the pointers to the first blocks in each of these two log chains, and each log block contains the pointer to the next log block.
Did you know?
We wrote about OpenZFS' L2ARC before!
ZIL Performance Improvements for Fast Media by Saji Nair
Saji's webinar session talks about improving the performance of the ZFS Intent Log on low latency devices. Currently ZFS ensures strict ordering of synchronous operations, but there are some operations that do not require this level of strict ordering, specifically operations that do not involve name space operations (create, rename, delete, etc).
By making these synchronous changes no longer interdependent, they can be done in parallel, lowering the latency of the operations, especially on newer devices like NVMe, that are not limited by the SATA/SAS interface.
These newer devices also have much lower write latencies than were imaged when ZFS was created, so the ZIO pipeline may have too much overhead due to context switches to be suitable for the ZIL, so instead “direct dispatch” may be more suitable, since the latency of the device is lower enough. The talk also covered how to maintain the consistency required for the namespace operations.
Sequential Reconstruction by Mark Maybee
Here's why this is interesting - it's actually the first on the new sequential resilver feature that is being added. The talk starts by clarifying terminology (e.g. etymology of resilver) but also explaining the pros and cons of each approach.
The new “spacemap powered” rebuild, will be called “Sequential Resilver”. Unlike the previous optimization for the healing resilver, this new feature is fully sequential, scanning the disks in block order without reading the block pointers at all. This is much faster than the normal block pointer based-based scrub/resilver, as it uses the spacemap data structure to rebuild all allocated space in a mirror in sequential order, providing the highest possible throughput.
Once a sequential rebuild is complete, it automatically triggers a full scrub to verify the checksums. In the end this means that the total process is longer, since the faster rebuild is followed by the full scrub anyway, however, once the rebuild step is complete the redundancy of the pool is restored, meaning a successive failure will not fault the pool. The talk also explained why this approach is not possible with RAID-Z.
dRAID, Finally! by Mark Maybee
So, dRAID! the feature that gave us the concepts of the sequential rebuild and metadata allocation classes. dRAID introduces the concept of distributed virtual spare devices and allows every disk in the pool to participate in the rebuild process, rather than just the members of the particular vdev that contains the failed disk.
dRAID avoids some of the logical layout problems of RAID-Z by ensuring that every allocation is a multiple of the full data+parity size, rather than just parity+1. This means that every allocation starts at a predictable offset, so the sequential resilver feature can work without requiring access to the block pointer.
With small blocks this can lead to a lot more padding and therefore wasted space, which is why dRAID introduced the special allocation classes feature, allowing such small blocks to be stored on a separate mirrored vdev, alleviating this issue.
Some of the major advantages of dRAID are: spare spindles are leveraged, data is randomly distributed so redundancy groups are decoupled from the number of data drives, reconstruction can leverage all drives, and sequential resilver works. The drives that would normally be reserved as spares are not left unused like in RAID-Z, providing the additional performance from the extra spindles. Instead the requested number of spare drives are constructed virtually, from chunks of space on every drive in the dRAID, more on how this helps shortly.
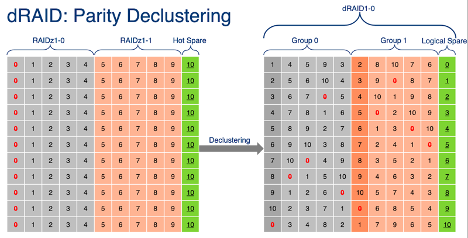
In dRAID the data is distributed according to a precalculated permutation array, so when physical disk 0 dies, rather than losing all the data in that column and having to reconstruct it using the parity in the remaining members of that vdev, a bit of data from each logical disk is lost, and the reconstruction will read from every disk in the pool, increasing performance.
Additionally, because the spares are distributed in the same fashion, during the rebuild, the system will read from every disk, and write to every disk, allowing the rebuild process to take full advantage of all available disk I/O to restore resiliency. The layout changes in dRAID also allow it to take advantage of sequential resilver, so the first stage of the rebuilt process, to restore the parity level, is much, much faster.
Check back for more!
Want to read more? No problem, just click here to check out our walk through of the afternoon sessions.







