






FreeBSD has a very mature and high-performance network stack which has evolved over the life time of the Internet. While new protocols are constantly being developed, the venerable Transmission Control Protocol (TCP) still accounts for most global traffic. As advancements to network protocols and congestion control algorithms are developed, they are frequently implemented for and merged into the FreeBSD kernel. In many cases they are left off by default at first and are configurable via sysctl options.
New features being introduced through optional controls has upsides and downsides. An upside of optional controls is that if a change is detrimental to a certain traffic profile, then it is easy to revert back to the previous behaviour. It has the downside of adding a lot of options which can be difficult to understand the costs and benefit of enabling, unless you are experienced with the internal workings of TCP.
sysctl options carry online documentation that can be exposed with the -d flag, but even those explanations can be cryptic. The excellent Calomel.org FreeBSD Network Tuning and Performance Guide has an example sysctl.conf file that explains many of the TCP and Network stack sysctl, and explains their functionality and use.
Even with this, it can be hard to tell if enabling an option is offering a real benefit to your traffic and sometimes it can be hard to tell if the option ishaving any effect at all. Here we look at some of the sysctl options available in the latest version of FreeBSD and show the impact they have on traffic when viewed with Wireshark.
Our previous FreeBSD support article on network performance troubleshooting covered in detail the fundamentals of network performance. That is an article to review if you aren’t very familiar with network protocol performance. In summary, we describe networks in terms of their latency (how long it takes for the information to propagate) and bandwidth (how many bits we can put into the network at once). TCP uses these measures to estimate the capacity of the network with a metric called the congestion window (cwnd), a transfer tries to balance the capacity of the network with the capacity of the receiving host, the receiving host advertises how many packets it is willing to let us send to it at a time by signaling its receive window (rwnd). The number of packets we can send at once, that we can have “in flight”, is the minimum of the cwnd and the rwnd.
Initial Window
The Initial Window (IW) is the value that the congestion window is set to when a new TCP connection is created. The size of the Initial Window governs how many packets we can send in the first round trip time of the connection, where data is sent, and it sets the start point for growing our estimate of the network’s capacity. If our data transfer is transactional at the start or if our transfer is small enough, a larger initial window can greatly improve performance by reducing transfer time.
The TCP IW has changed over time; the IETF currently recommends an IW of 10 segments where it was previously 3 segments. Larger Initial Windows have been tested in literature and found to offer performance benefits, which is why the IETFs recommendation is considered to be a little conservative.
Reno based TCP congestion control algorithms follow a pattern of exponential increase during their slow start phase. If we plot two TCP connections in wireshark we can see that, with a larger IW, the exponential curve is steeper for IW40 vs IW10.
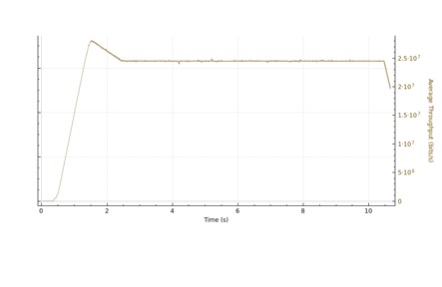
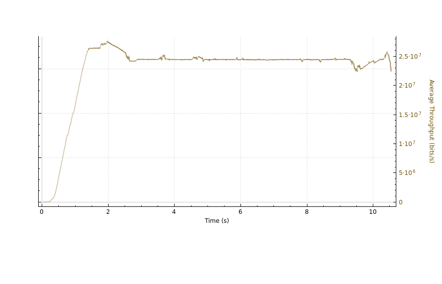
In FreeBSD 13, the TCP Initial Window is controlled by the:
net.inet.tcp.initcwnd_segments sysctl.
# sysctl -d net.inet.tcp.initcwnd_segments
net.inet.tcp.initcwnd_segments: Slow-start flight size (initial congestion window) in number of segments
# sysctl net.inet.tcp.initcwnd_segments
net.inet.tcp.initcwnd_segments: 10
Did you know?
Improving your FreeBSD infrastructure has never been easier. Our teams are ready to consult with you on any FreeBSD topics ranging from development to regular support.
The default IW in FreeBSD is 10 which is the value recommended by the IETF. 10 segments is around 12-15k of data depending on the segment size. This value might be conservative for your workloads, but if you are considering changing this, then it is worth evaluating the modes in your traffic distribution.
We can see the effect of changing the initial window by performing transfers with different sizes and looking at their completion times. The following script tries two different sizes, across 4 different initial windows and saves the total execution time for iperf3 to move the transfer size:
#!/bin/sh
set -e
for size in 65k 1m
do
for x in 3 10 20 40
do
sudo sysctl net.inet.tcp.initcwnd_segments=${x};
for y in $(jot 20)
do
/usr/bin/time -a -o iperf3-iw${x}-${size}.out iperf3 -c iperf3.example.com -n ${size}
sudo -v
done
done
done
We can look at the resulting output files with ministat to see if there is any improvement between each size:
$ ministat iperf3-iw3.out iperf3-iw10.out iperf3-iw20.out iperf3-iw40.out
x iperf3-iw3.out
+ iperf3-iw10.out
* iperf3-iw20.out
% iperf3-iw40.out
+--------------------------------------------------------------------------+
| * + % x |
| * + % x |
| * + % x x |
| * + % % x x |
| * + % % x x |
| * + % % x x |
| * * % % x x |
| * * % % x x |
| * * @ % % x x |
|* * * @ % % # x x x|
| |_MA__||__A__| |__M__A____| |______AM_____| |
+--------------------------------------------------------------------------+
N Min Max Median Avg Stddev
x 20 0.86 0.9 0.87 0.868 0.0095145318
+ 20 0.81 0.83 0.82 0.82 0.0045883147
Difference at 95.0% confidence
-0.048 +/- 0.00478065
-5.52995% +/- 0.52619%
(Student's t, pooled s = 0.00746924)
* 20 0.8 0.82 0.81 0.8115 0.0048936048
Difference at 95.0% confidence
-0.0565 +/- 0.00484226
-6.50922% +/- 0.529354%
(Student's t, pooled s = 0.0075655)
% 20 0.83 0.86 0.84 0.8435 0.0074515982
Difference at 95.0% confidence
-0.0245 +/- 0.00546953
-2.82258% +/- 0.619167%
(Student's t, pooled s = 0.00854554)
At 65k, increasing the IW from the old default of 3 to 10 offers a 6% improvement. The time to transfer decreases (less time is better) for each of these apart from when IW is 40. With an IW of 40 we are hitting bottle neck of the upstream link where this test was run from.
When we transfer larger amounts of data, the improvement is averaged out against the longer total transfer time:
$ ministat iperf3-iw3.out iperf3-iw10.out iperf3-iw20.out iperf3-iw40.out
x iperf3-iw3.out
+ iperf3-iw10.out
* iperf3-iw20.out
% iperf3-iw40.out
+--------------------------------------------------------------------------+
| % |
| % |
| +x O |
| +x O |
|*+x O |
|*+x O |
|*+x O |
|*+x O |
|*@x O x |
|*@x O x |
|*@x O x |
|*@x O x |
|*@# O x |
|*@# O x |
|*@# O x |
|*@# O x |
|*O# O x |
|*O# Oxxx |
|*O# Oxxx |
|*O#x O*xx* x|
||||_______________________________A_A______________________________||_| |
+--------------------------------------------------------------------------+
N Min Max Median Avg Stddev
x 40 0.86 3.31 2.02 2.02275 1.1697819
+ 40 0.81 3.12 1.965 1.96525 1.1598541
No difference proven at 95.0% confidence
* 40 0.8 3.23 1.955 1.9645 1.1678711
No difference proven at 95.0% confidence
% 40 0.83 3.12 1.975 1.97175 1.1426485
No difference proven at 95.0% confidence
At 1M of data transferred there is not an observable benefit to changing the IW on this link, but that doesn’t mean that larger IWs won’t offer a benefit on higher bandwidth links.
Values for the Initial Window up to 100 segments have been tested and are used in production. However, before widely deploying any change like this, it is important to evaluate its side effects on other traffic. If you change this value, it is worth exploring loss on TCP flows across the system to see if you are impacting your own traffic to other hosts negatively.
TCP Segment Offload (TSO)
TCP Segment OffLoad (TSO) is a mechanism that reduces the number of transfers that need to be made between the network stack and the network card when sending packets. TSO allows the TCP stack to pass large blocks of data to the network card, which the card then breaks down into TCP segments. TSO enables a large performance improvement for the sending host - the host has to perform far fewer transactions to send packets and instead can rely on the ability of the network card to segment and quickly send packets.
Because TSO depends on the network card to correctly create the packets which are sent, there can be issues with the packets generated by TSO. TSO will appear in packet captures from a sending host as very large packets, these do not appear on the wire.
One sign that TSO is being used is the presence of TCP segments larger than the network interfaces MTU. TSO segments can be very confusing the first time you see them in a packet capture, they look like impossible packets. If you are investigating large bursts of packet loss or connectivity drops between hosts, TSO might be the culprit. TSO is great for exposing implementation issues with switches, DPI firewalls and other boxes that have slightly odd custom TCP stacks.
TSO is advertised per interface and address family via the TSO4 and TSO6 flags.
# ifconfig igb0
igb0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=e507bb<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,JUMBO_MTU,VLAN_HWCSUM,TSO4,TSO6,LRO,VLAN_HWFILTER,VLAN_HWTSO,RXCSUM_IPV6,TXCSUM_IPV6>
ether ac:1f:6b:46:9e:da
inet 192.168.1.13 netmask 0xffffff00 broadcast 192.168.1.255
inet6 fe80::ae1f:6bff:fe46:9eda%igb0 prefixlen 64 scopeid 0x1
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
nd6 options=23<PERFORMNUD,ACCEPT_RTADV,AUTO_LINKLOCAL>
TSO can be turned off via the net.inet.tcp.tso sysctl and by changing the flags on the network interface:
# sysctl net.inet.tcp.tso=0
# ifconfig igb0 -tso4 -tso6
Depending on the interface, this might cause the link to stall while it reconfigures.
There are blanket recommendations to turn off TSO; however, you should avoid turning TSO off until there is a demonstrated reason to do so, as the host performance benefits offered by TSO are quite large.
TCP Buffer Tuning
The TCP receive window (rwnd) indicates how many bytes the receiving host is able to buffer and reassemble at any one time. It is directly linked to the size of the socket buffers on the host. If your link has a high BDP, the size of the socket buffers might be too small to accommodate the number of packets that can be sent at once (these packets are considered ‘in flight’) and the transfer will become limited by the size of the buffer. In these situations, TCP on FreeBSD will autotune the socket buffers increasing their size. The default buffer sizes are acceptable for many links on the Internet, but if you have particularly high bandwidths or very high delays then you might experience rwnd throttling.
The algorithm that tunes these buffers runs at a multiple of the round trip time of the connection. If the link has a lot of latency the connection will be throttled by the receive window size, a fixed step of traffic being released each RTT allowing the connection to grow in throughput very slowly.
In the three throughput plots from Wireshark below (you can find these in the statistics menu), we can see a step function in the window size over time, rather than an exponential or additive growth as we saw in the IW plots earlier. When we zoom in we can see two lines, the thick blue line shows the packets used to calculate the in flight window and the thin green line shows the advertised rwnd. We can see from the zoomed plot that the rwnd is capping off the number of bytes that can be sent at a time and when it updates, the window size jumps up to meet it. This shows that the connection is limited by something other than the congestion window and tuning the rwnd defaults can help.
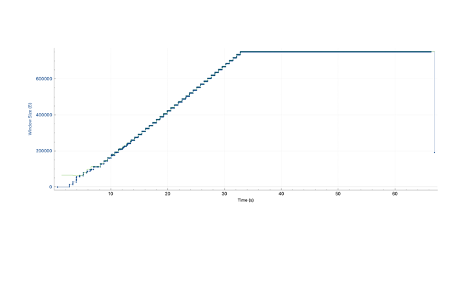


The receive buffer must be fully allocated on the host for the smooth operation of a transfer. If it were too small, then packets would be dropped and the connection would stall. Tuning all connections up like this means that the host is allocating more memory for these transfers. It will depend on your environment if this sysctl is correct to manipulate or not.
How do you determine the right buffer size to use? The connection needs to be able to accommodate the bandwidth delay product (BDP) of the network. The BDP is calculated by multiplying the bandwidth of the network by the delay. A network connection at 100Mbit/s with a delay of 10ms has a BDP of 125 kilobytes. The above example is from a geo satellite link and it shows an extreme case where the BDP of the network is roughly 4 Megabytes!
If you are running site to site services, it might be the case that your connections will fit into a small number of delays. If you have a public server, then you might need to tune this value for an average or worst-case delay for your incoming traffic.
The best way to determine this is to sample the traffic you serve and observe the delays you see in production.
You can control the receive buffer space for tcp connections via the net.inet.tcp.recvbuf_max sysctl.
# sysctl net.inet.tcp.recvbuf_max
net.inet.tcp.recvbuf_max: 2097152
When tuning, you might want to keep the default size small, while allowing large increases when the buffer size limit is hit. The following sysctls are worth experimenting with:
• net.inet.tcp.recvbuf_max
• net.inet.tcp.recvspace
• net.inet.tcp.sendbuf_inc
• net.inet.tcp.sendbuf_max
• net.inet.tcp.sendspace
Conclusion
The FreeBSD kernel TCP stack offers a lot of opportunities to tweak different performance features. The options it includes allow a lot of flexibility in the configuration of machines without having to do custom kernel builds. The large number of options can make it hard to understand what is valuable to change and what is not. When you are considering changing a network stack default, it is good practice to try and understand what the option controls and if changing it will offer a benefit to your traffic.
There is a lot of information available about these controls, but it can take a little digging to uncover. Thankfully, most Internet protocol work is done in the open and there is a wealth of resources available that show examples of how these options can be set.
Want to take FreeBSD networking to the next level? Learn how network offloading and socket splicing (SO_SPLICE) can streamline data flow and reduce overhead in our latest article, Network Offload and Socket Splicing (SO_SPLICE) in FreeBSD.







