






The Challenge:
When Backups Are No Longer Enough
The client required a pair of high-performance servers with real-time mirroring to support their Proxmox Virtualization environment, eliminating the risk of data loss while enabling rapid failover. Traditional backup-based disaster recovery approaches were judged to be insufficient—the client needed:
- Zero data loss in the event of a server or network failure
- Seamless failover capability that could be executed quickly and confidently
- High performance to support demanding virtualized workloads
- Resilience against multiple failure modes, including switch failures and complete server outages
The infrastructure consisted of two identical high-spec servers with performant NVME drives, but the storage infrastructure had to be fundamentally rethought to meet these goals.

The Solution:
Designing Failure Out of the Storage Layer
Klara designed a high-availability architecture where both servers actively mirror data to each other in real-time. Rather than relying on Proxmox’s built in support for ZFS asynchronous replication - which cannot achieve a Zero RPO, since any data newer than the most recently replicated snapshot would be missing during failover. Klara implemented synchronous mirroring at the storage layer using ZFS's native capabilities.
The two servers were connected through redundant network paths (two separate switches and separate fibre paths), ensuring that even a switch failure wouldn't interrupt the mirroring process. Each server's NVMe drives are shared with its partner via a network storage protocol, allowing both machines to construct ZFS pools that span drives from both physical locations.
This design ensures that every write operation is committed to drives on both servers before being acknowledged to the application—achieving the coveted Zero RPO. In the event of a server failure, the surviving server can immediately take over both workloads with no data loss and no lengthy recovery process.
The Solution:
Designing Failure Out of the Storage Layer
Klara designed a high-availability architecture where both servers actively mirror data to each other in real-time. Rather than relying on Proxmox’s built in support for ZFS asynchronous replication - which cannot achieve a Zero RPO, since any data newer than the most recently replicated snapshot would be missing during failover. Klara implemented synchronous mirroring at the storage layer using ZFS's native capabilities.
The two servers were connected through redundant network paths (two separate switches and separate fibre paths), ensuring that even a switch failure wouldn't interrupt the mirroring process. Each server's NVMe drives are shared with its partner via a network storage protocol, allowing both machines to construct ZFS pools that span drives from both physical locations.
This design ensures that every write operation is committed to drives on both servers before being acknowledged to the application—achieving the coveted Zero RPO. In the event of a server failure, the surviving server can immediately take over both workloads with no data loss and no lengthy recovery process.

Pool Layout:
Storage That Spans Both Physical Locations
Klara designed and deployed ZFS pools that intentionally spanned both servers, using mirrored VDEVs where each mirror paired one local drive and one remote drive from the partner server.
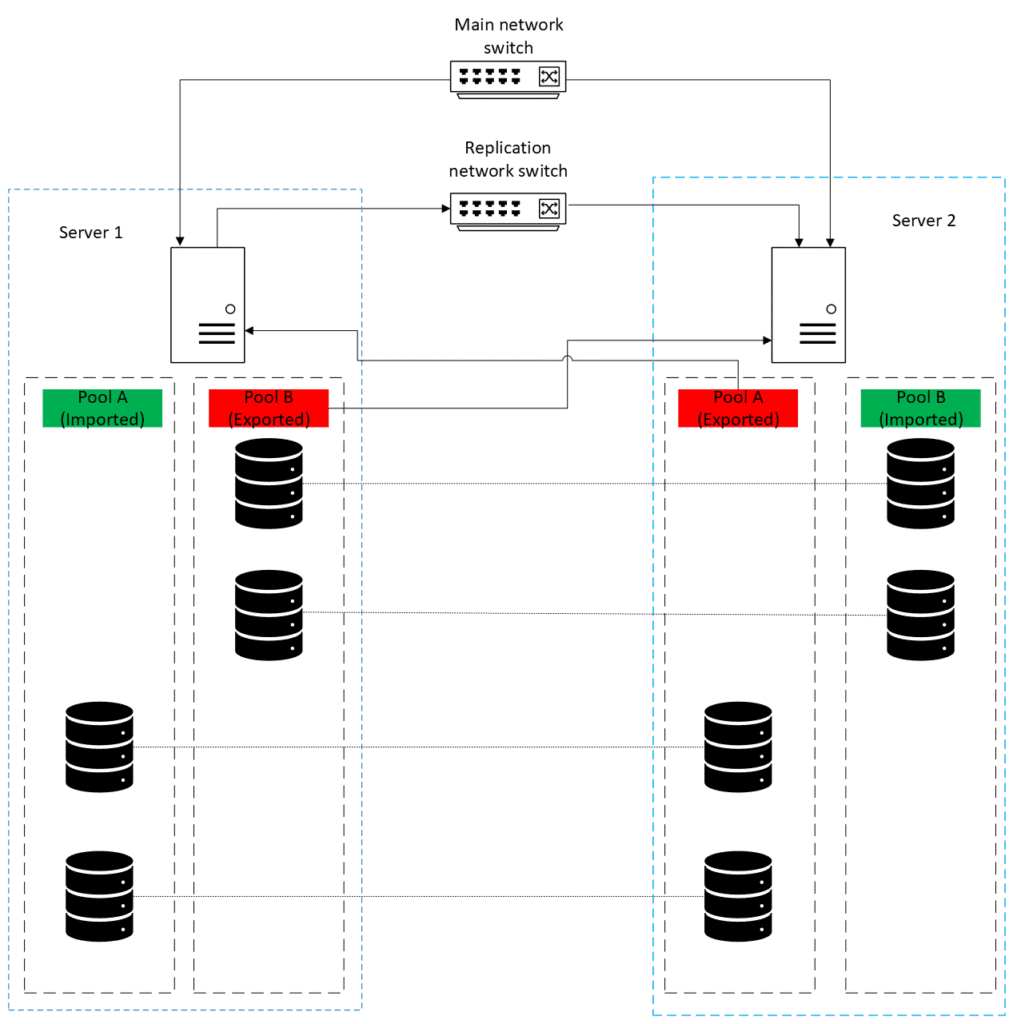
Key Design Elements
12 Mirrored VDEVs per Pool
Cross-Server NVMe Mirroring

Active-Active Operation
Under normal conditions, each server is the primary for one pool, distributing the workload.
Full Failover Capability
Multihost Protection
With the help of ZFS's internal mechanisms for keeping mirrored drives in sync, any network delays or momentary connectivity drops do not result in data loss. ZFS automatically catches the drive that experiences a momentary drop up with the latest state of the pool once connectivity is restored, and the transaction model ensures consistency is maintained throughout.
Optimizing for NVME Performance
The all-NVMe storage configuration created an opportunity to push performance far beyond default ZFS behaviour. ZFS tuning parameters are designed to perform safely across a wide range of hardware, particularly traditional spinning disks, where aggressively dispatching I/O can cause severe latency spikes. While those defaults provide reliability, they also leave significant performance untapped on modern NVMe drives, which thrive with higher queue depths and more concurrent operations.
Klara applied a comprehensive set of tuning parameters to maximize the NVMe drives' capabilities:
I/O Scheduler Tuning:
- Increased synchronous read/write queue depths to allow more concurrent operations
- Raised asynchronous read/write limits to improve throughput for background operations
Write Performance Optimization:
- Increased the ZFS dirty data limit, allowing more write aggregation before flushing to disk
- Adjusted the commit timeout to reduce unnecessary waiting when NVMe drives can handle writes immediately
- Tuned aggregation limits for non-rotating media to better utilize NVMe bandwidth
These optimizations were carefully validated through iterative testing to ensure they improved performance without introducing conflicts or impacting stability.

Validation and Testing:
Proving Performance Improvements
Performance tuning requires rigorous testing to validate that changes actually improve the metrics that matter. We employed fio (Flexible I/O Tester) to model realistic storage workloads and measure the system's response.
Testing methodology:
- Ran multiple test cycles covering sequential reads, random reads, and random writes
- Tested with varying numbers of concurrent jobs (1, 8, and 16) to understand scaling behavior
- Compared pre-tuning and post-tuning results across all test configurations
There weren't theoretical optimizations – they translated directly into faster virtual machines, smoother workloads, and shorter backup windows.

Business Impact:
Reliability Without Recovery
No data or consistency loss during failover
Every write operation is acknowledged to the application only after being safely written to both physical locations. This synchronous mirroring approach means that when a failure occurs:
- No committed transactions are lost
- Database consistency is maintained
- There's no need to restore from backups or reconcile data discrepancies
- Failover is a clean operation, not a recovery operation
ZFS's transaction model and ZIL (ZFS Intent Log) handling ensure that even if a server fails mid-write, the surviving server has all the data needed to continue seamlessly. The ZIL replay mechanism handles any in-flight operations exactly as it would during a local unexpected reboot scenario.
Business Impact:
Reliability Without Recovery
No data or consistency loss during failover
Every write operation is acknowledged to the application only after being safely written to both physical locations. This synchronous mirroring approach means that when a failure occurs:
- No committed transactions are lost
- Database consistency is maintained
- There's no need to restore from backups or reconcile data discrepancies
- Failover is a clean operation, not a recovery operation
ZFS's transaction model and ZIL (ZFS Intent Log) handling ensure that even if a server fails mid-write, the surviving server has all the data needed to continue seamlessly. The ZIL replay mechanism handles any in-flight operations exactly as it would during a local unexpected reboot scenario.
Faster systems across the board
43% improvement in random writes, 60%+ improvement in sequential reads.
The ZFS tuning optimizations delivered substantial performance improvements:
- Random write performance (43% increase): Critical for VM workloads where multiple virtual machines generate concurrent, random I/O patterns. Faster random writes mean more responsive VMs and better user experience.
- Sequential read performance (68% increase): Essential for backup operations and large data transfers. Faster sequential reads dramatically reduce backup windows (RPO) and improve data recovery capabilities (RTO).
The infrastructure now supports growth without performance becoming a bottleneck, driven by tuning ZFS for modern NVMe hardware, so the storage system can fully utilize the high-speed drives instead of being limited by conservative defaults designed for slower media.

The team now executes failovers confidently
Klara worked with the client's team to develop and document comprehensive failover procedures, then conducted training drills to ensure the operations team could execute them confidently. The documented playbook covers:
- Planned failover procedures for maintenance windows
- Emergency failover procedures for unexpected outages
- Recovery and resynchronization procedures when the failed server returns
- Drive replacement procedures for hardware failures
Having practiced the failover process, the operations team can now execute it quickly and confidently when needed—whether for planned maintenance or emergency response. This operational readiness transforms disaster recovery from a theoretical capability into a practical, tested procedure.

At a Glance
Up to 68% Performance Gains
Zero-RPO Architecture
Production-Ready Failover Procedures
What’s Next:
Designing for Resilience, Not Recovery
This implementation demonstrates the power of combining ZFS's enterprise storage capabilities with thoughtful architecture and performance optimization.
The same principles—synchronous mirroring, NVMe-optimized tuning, and comprehensive failover planning—can be applied to a wide range of high-availability requirements.
Klara continues to work with organizations that need:
- High-availability storage solutions with zero or near-zero RPO
- ZFS performance optimization for modern NVMe and SSD storage
- Disaster recovery planning and failover procedure development
- Storage architecture consulting for demanding workloads
What’s Next:
Designing for Resilience, Not Recovery
This implementation demonstrates the power of combining ZFS's enterprise storage capabilities with thoughtful architecture and performance optimization.
The same principles—synchronous mirroring, NVMe-optimized tuning, and comprehensive failover planning—can be applied to a wide range of high-availability requirements.
Klara continues to work with organizations that need:
- High-availability storage solutions with zero or near-zero RPO
- ZFS performance optimization for modern NVMe and SSD storage
- Disaster recovery planning and failover procedure development
- Storage architecture consulting for demanding workloads
