







Fast Dedup Economics When Deduplication Beats Buying New Disks
Storage planning used to follow a predictable pattern. When capacity approached its limit, administrators added more disks. That model worked when infrastructure was smaller and disk density increased rapidly with each hardware generation. Modern infrastructure has changed the equation. Virtual machines, container registries, CI pipelines, backup systems, and logging platforms produce enormous volumes of duplicated data. In many storage environments, the majority of blocks written to disk already exist elsewhere in the system.
Deduplication changes the economics of storage by recognizing those repeated blocks and storing them only once. Instead of writing multiple copies of identical data, the filesystem writes a single block and replaces duplicates with references. Applications continue to see complete datasets, but the physical storage footprint shrinks dramatically.
Within the ZFS ecosystem, this concept has become particularly relevant, as modern OpenZFS development has significantly improved the performance characteristics of deduplication. Understanding when deduplication beats buying more disks requires examining how modern ZFS deduplication works, how the economics have changed, and where the tradeoffs still remain.
Storage Economics in Modern Infrastructure
The cost of storage is often discussed in terms of price per terabyte, but in practice that metric hides most of the real expenses. Adding disks rarely means inserting a few drives and calling it done because capacity growth typically involves several cascading costs:
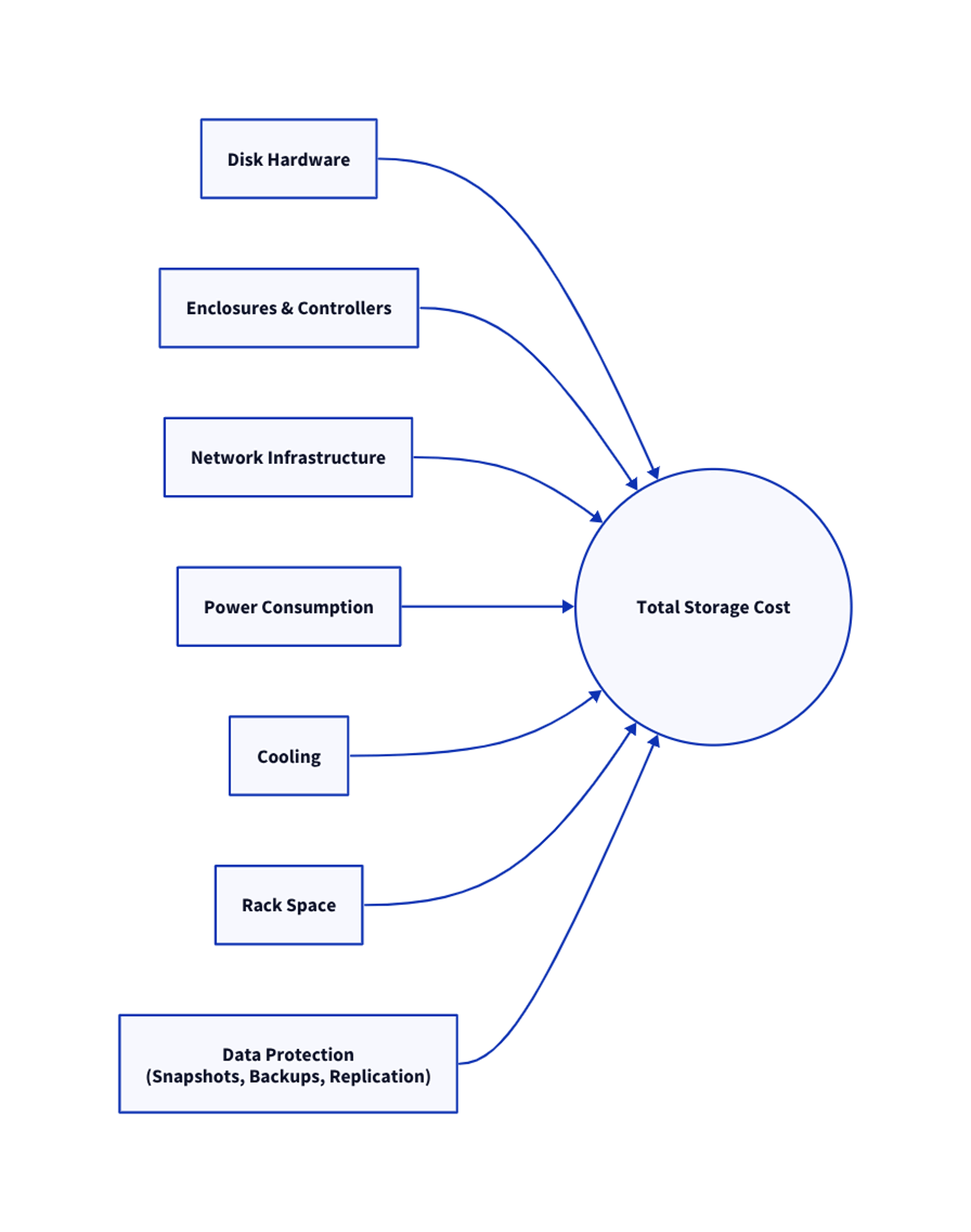
There are hardware expansions beyond just the additional drives, as storage arrays require additional enclosures, controllers, and network connectivity. Large pools may require more SAS expanders or additional storage nodes.
Operational costs grow alongside capacity. These include increased power consumption, cooling requirements, and rack space.
Data protection multiplies the storage footprint. Snapshots, replication, and backup retention often cause the logical data stored in an organization to be several times larger than the active dataset.
These factors show that the cost of storing a terabyte is not simply the cost of a disk. It is the cost of the entire storage ecosystem that supports that disk.
Deduplication approaches the problem differently. Instead of expanding capacity to match logical data growth, deduplication reduces the amount of unique data stored on disk. If the infrastructure contains large amounts of repeated blocks, deduplication allows the same physical storage to hold far more logical data.
How Deduplication Works
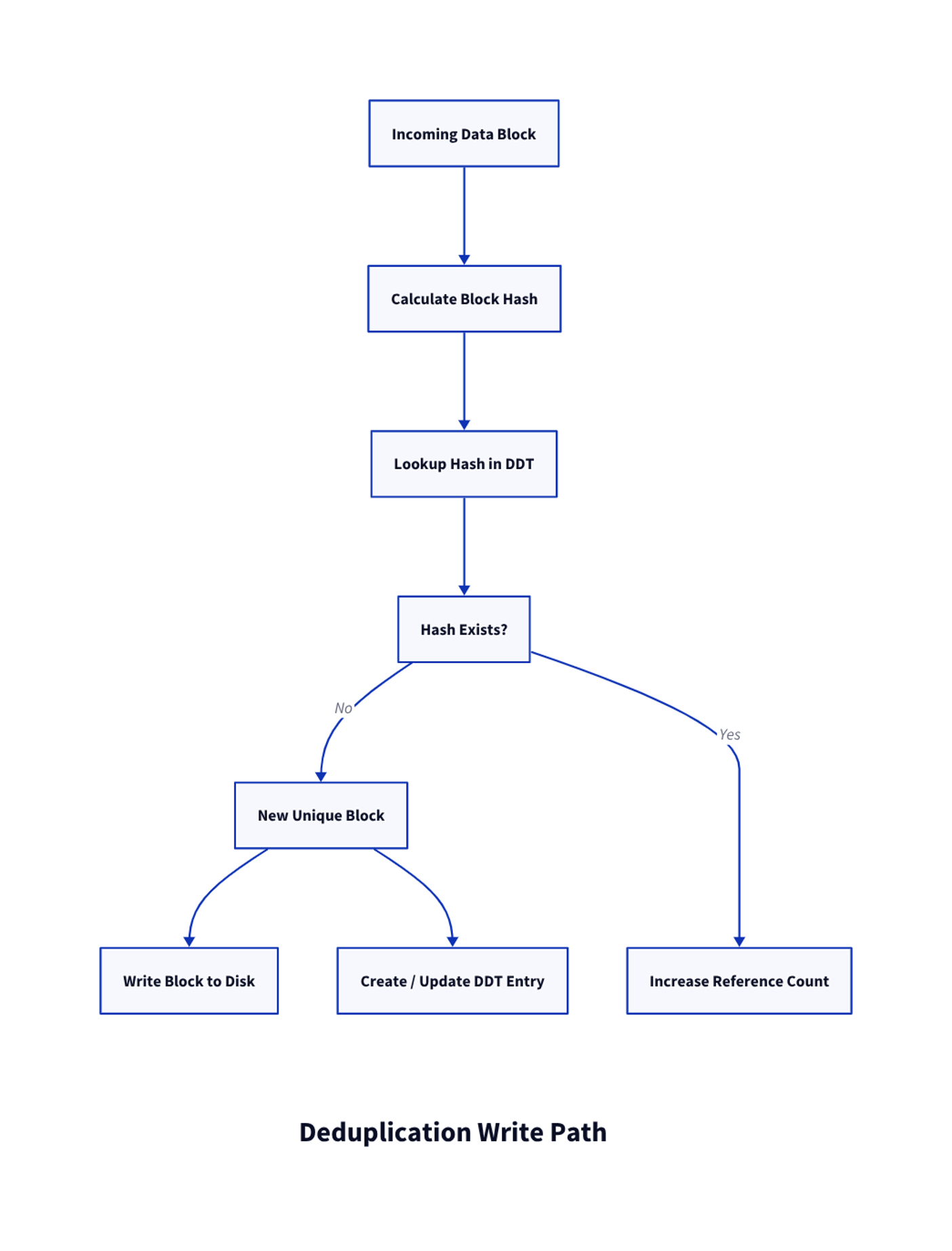
Deduplication identifies identical blocks of data and stores them only once. When data is written to disk, the storage system divides it into blocks and calculates a cryptographic hash for each block. This hash acts as a fingerprint that uniquely identifies the block’s contents.
The system then checks whether the fingerprint already exists in its deduplication index. If an identical block already exists, the filesystem does not write the data again. Instead, it creates a reference pointing to the original block.
Only blocks that have never been seen before are written to disk. The effectiveness of deduplication depends entirely on how much repetition exists within the dataset. Environments with repeated system images, similar application stacks, or frequent incremental backups often contain enormous amounts of duplicate data.
ZFS and the Foundations of Deduplication
ZFS was designed with copy-on-write semantics, which means as data is modified, ZFS writes new blocks instead of overwriting existing ones, and metadata pointers are then updated to reference the new blocks. This design makes snapshots extremely efficient, which preserves pointers to existing blocks rather than copying data. Clones extend this concept further. A clone initially shares all blocks with its parent dataset and only diverges when changes occur.
These features already provide a limited form of block sharing. However, block sharing in this model occurs only within the same snapshot lineage. Two independent datasets containing identical files will still store their own copies of the blocks.
Deduplication extends this sharing mechanism across the entire storage pool. When deduplication is enabled on a dataset, ZFS checks each incoming block against a global index before writing it to disk. If the block already exists anywhere in the pool, ZFS simply references the existing copy. The result is a global block sharing system that consolidates duplicated data across datasets, snapshots, and clones.
The central structure behind ZFS deduplication is the Deduplication Table, or DDT. The DDT stores the hash of every unique block along with metadata describing the physical location of the block and the number of references pointing to it.
When a new block is written, ZFS calculates its hash and searches the DDT for a matching entry. If the hash already exists, the block is not written again. Instead, the reference count for the block increases and the filesystem pointer references the existing location.
Fast Dedup in Modern OpenZFS
For many years, ZFS deduplication had a reputation for being slow. The original implementation required frequent updates to the deduplication table as part of each transaction group. This could lead to cases where the same block of the DDT was updated multiple times in rapid succession, wasting disk bandwidth. Before fast dedup, the size of the DDT could also grow unbounded, causing severe performance issues. When all DDT entries were not able to be kept in the ARC cache, the system had to perform random metadata reads from disk, which slowed down each write operation.
These metadata lookups often became the dominant performance bottleneck in deduplicated systems, which is why much older documentation, blog posts, and forum discussions discouraged enabling deduplication.
Recent OpenZFS development has significantly improved this situation. The Fast Dedup project redesigned aspects of how the deduplication table is updated and maintained.
Instead of forcing every block deletion or reference update to trigger expensive metadata operations immediately, modern implementations defer some of this work and perform cleanup asynchronously. Improvements in caching behavior and DDT update patterns also reduce random I/O pressure on dedup metadata.
The result is not that deduplication becomes free, but that the historical performance penalties have been reduced enough for the feature to be considered in carefully selected production workloads.
Functionally, the Fast Dedup project introduces the obsolete flag, which allows ZFS to mark blocks as no longer needed without immediately performing heavy dedup table updates. By decoupling block deletion from immediate DDT cleanup, the system avoids the “deletion death spiral” that previously affected large deduplicated pools.
This asynchronous cleanup, combined with more sequential and log-structured handling of DDT updates, shifts much of the work away from the synchronous write path and into background processing.
The DDT in RAM Myth
Early ZFS documentation often included a simple rule of thumb that the deduplication table should fit entirely in RAM for acceptable performance. If you have worked with ZFS for some time, you have probably heard the familiar guideline of roughly 1 GB of RAM per 1 TB of deduplicated storage.
Historically this advice was somewhat accurate because when the DDT could not fit within the ARC memory cache, lookups would have to be serviced by spinning disks. In early deployments this meant that enabling deduplication on large pools could require enormous amounts of memory. Systems storing hundreds of terabytes of unique data might require hundreds of gigabytes of RAM to maintain acceptable performance.
Modern OpenZFS deployments have changed this equation significantly through improvements in caching and metadata storage. Even more important is the introduction of special allocation class vdevs. These devices create dedicated storage tiers for specific types of allocation, such as metadata, small blocks, and the dedup table. When implemented using mirrored NVMe drives or ultra-low latency media such as Optane, metadata access latency becomes extremely low. The dedup quota feature introduced as part of fast dedup can be used to ensure that the DDT does not outgrow the dedup class storage, avoiding the performance cliff experienced once the DDT spills over onto slower devices.
Placing metadata and deduplication table entries on these devices does not eliminate the need for memory. However, it significantly reduces the performance penalty when DDT lookups fall outside the ARC cache.
The practical result is that you no longer need massive RAM footprints to operate deduplicated pools. By placing metadata on extremely fast solid-state devices, the cost of supporting large DDT structures becomes far more manageable. This architectural shift has made deduplication economically viable in many environments where it was previously considered impractical. Once this RAM limitation becomes less restrictive, another concern often raised about deduplication is whether hashing itself introduces significant CPU overhead.
Hashing is no longer the bottleneck
Another concern often associated with deduplication is CPU overhead. This is because every block written to disk must be hashed so that the filesystem can determine whether that block already exists elsewhere in the pool.
Early discussions about deduplication frequently warned that hashing operations could consume significant CPU resources. In modern systems, this concern is largely outdated, as modern processors include hardware acceleration features specifically designed for cryptographic operations.
Instruction set extensions such as SHA-NI allow cryptographic hash calculations to be executed extremely efficiently and because of these hardware improvements, the computational cost of hashing blocks is now very small compared with other parts of the deduplication pipeline.
In practice, the dominant bottleneck in deduplication systems is no longer CPU cycles. Instead, it is the latency of metadata operations, particularly the speed at which the deduplication table can be accessed and updated.
This is why fast metadata storage and effective caching strategies are now far more important than raw CPU performance when designing deduplicated ZFS systems. Once hashing overhead is no longer a limiting factor, the next practical consideration appears later in the I/O path, which is how deduplication affects read behavior.
Fragmentation and Read Amplification
Deduplication introduces an important tradeoff that is sometimes overlooked. When deduplication is heavily used, many files may reference blocks that are physically scattered across different regions of the storage pool. A file that appears logically contiguous may actually consist of blocks shared with many other files.
This can convert sequential read operations into patterns that resemble random I/O. In highly deduplicated datasets, this fragmentation can increase read latency because the storage system must retrieve blocks from multiple locations rather than streaming them sequentially.
ZFS mitigates some of this effect through aggressive caching and intelligent allocation strategies. Frequently accessed blocks are likely to remain in memory, since only one copy of the deduplicated block needs to be stored in memory for all references to it to be accelerated. For many workloads this fragmentation is not particularly problematic. Virtual machines, databases, and many application workloads already generate random access patterns, so deduplication does not significantly alter their performance characteristics.
Sequential workloads are more sensitive, such as media streaming systems or large sequential file transfers, may experience reduced throughput if deduplication causes extensive block fragmentation. When you evaluate deduplication for a specific workload, understanding the access pattern of the data becomes an important part of the decision. Another consideration often emerges during that evaluation, especially in modern infrastructure where native encryption is increasingly common.
ZFS Deduplication and Native Encryption
Native encryption has become an increasingly common feature in modern ZFS deployments and there is this common assumption that enabling encryption automatically prevents deduplication from working. In practice, ZFS native encryption is fully compatible with deduplication, which means you can achieve both storage efficiency and data security at the same time.
ZFS encrypts data at the dataset layer before it is written to disk. When deduplication is enabled on encrypted datasets that share the same encryption context, the filesystem can still identify identical plaintext blocks and reference them appropriately. In these configurations, deduplication and encryption work together without sacrificing space savings.
The situation changes when data arrives at ZFS already encrypted by the application itself. Application-level encryption introduces randomization through initialization vectors and other cryptographic mechanisms before the data ever reaches the filesystem. Even if two files contain identical plaintext, their encrypted forms will appear completely different.
From the perspective of the deduplication engine, these ciphertext blocks are unrelated. Because of this, ZFS cannot detect duplicates when the data is encrypted upstream by the application. In those cases the deduplication ratio effectively becomes 1:1, since every block appears unique.
For most modern storage environments this distinction is important. If encryption is handled by ZFS itself, deduplication remains effective and both features can be used together. Problems typically arise only when encryption occurs earlier in the stack, such as within applications or external backup software.
Some backup systems address this limitation by performing deduplication before encryption takes place. In those architectures the storage system receives an already deduplicated data stream, preserving the space savings while still protecting the data at rest.
When Deduplication Beats Buying More Disks
The economics of deduplication become compelling when redundancy is high and infrastructure expansion is expensive.
Virtual machine storage is a classic example where hundreds of VMs running the same operating system share vast numbers of identical blocks. Backup repositories provide another strong candidate where daily incremental backups often contain only small changes from previous snapshots. Similarly, container registries frequently store multiple versions of images that share identical base layers.
In these environments deduplication collapses redundant blocks across datasets and dramatically reduces physical storage requirements. Instead of expanding the pool with additional vdevs, you can extract significantly more effective capacity from the existing hardware.
The decision to enable deduplication ultimately becomes an economic calculation. On one side is the cost of expanding the storage pool. This may involve purchasing additional disks, enclosures, and supporting infrastructure. On the other side is the cost of supporting deduplication metadata through RAM, NVMe metadata devices, and CPU resources.
With improvements in modern OpenZFS implementations and the widespread availability of NVMe devices, the cost of supporting deduplication has fallen significantly.
In environments where duplication ratios exceed roughly three to one or higher, deduplication can often become economically favorable compared with expanding the storage pool. However, the precise break-even point depends heavily on workload characteristics and hardware design.
Wrapping Up
ZFS deduplication has long been one of the most powerful yet misunderstood features. Early implementations required significant memory and introduced performance penalties that discouraged widespread adoption. Recent improvements in OpenZFS have reduced several of those barriers. Improved metadata handling, better caching behavior, and fast NVMe storage tiers make deduplication far more practical than it once was.
The engineers at Klara spend much of their time helping organizations design, deploy, and optimize ZFS storage systems for demanding workloads, whether the goal is improving performance, storage efficiency or evaluating features such as deduplication, a careful architectural approach transforms storage economics and extends the useful life of existing infrastructure far more effectively than simply adding more disks and hoping for the best.