







Applying the ARC algorithm to the ARC
ZFS is renowned for many of its different capabilities, from Copy-on-Write snapshots to triple parity distributed RAID, but today we are going to talk about the ZFS buffer cache implementation. ZFS uses the ARC (Adaptive Replacement Cache) to perform high-efficiency responsive caching to accelerate workloads. In this article we’ll learn about the ARC and how applying the algorithm twice leads to even greater performance
First, let's start with a quick refresher on what a cache does, and how it works.
What is a Cache?
Computer systems are made up of multiple tiers of storage, from the largest and slowest media used to store backups, to the fastest few kilobytes of memory built into each core of the processor. Generally, these tiers follow a simple trend, the faster they are, the more expensive and smaller the storage in that tier.
For example, on my laptop, the Ryzen 7 7840U CPU has 32 KiB of L1 instruction cache and 32 KiB of L1 data cache for each of its 8 cores. The memory can be accessed at a speed in excess of a terabyte per second and has a latency of a fraction of a nanosecond. This is amazingly fast. Yet, with only a few kilobytes of storage, and no persistence, it isn’t the right place to save documents. An L2 cache of 1024 KiB per core provides over a terabyte per second in speed, though with a slightly higher latency of 1-3 nanoseconds. Moving to the L3 cache, we find 16 MiB shared among all cores, with typical latency around 10 nanoseconds and bandwidth exceeding 400 gigabytes per second. Next, the main system memory—32 GiB of RAM—offers bandwidth above 100 gigabytes per second, with a latency of 15-30 nanoseconds.
As you can see, each tier gets bigger, but also slower. The trade-off is almost always cost, the fast SRAM used for the L1 cache is just too expensive to have gigabytes of it in your laptop. Then we get to persistent storage, the NVMe in my laptop can read at 7 GiB/sec and write at 5 GiB/sec, with a latency in the 10s or 100s of microseconds. A regular spinning hard drive is available in much larger capacities, but generally can only read and write at 250 MiB/sec with a latency of 4 milliseconds.
From this brief overview of just one machine, we can clearly see the different tiers of memory.
"We are therefore forced to recognize the possibility of constructing a hierarchy of memories, each of which has greater capacity than the preceding but which is less quickly accessible." Von-Neumann, 1946.
How does a cache work?
A cache is a temporary copy of data kept on a faster tier of memory to make it faster to access, similar to how you might gather all of the receipts you need before trying to calculate your annual tax return. The difference is that the cache is a copy, not the original so that it can be replaced with different data when it is needed. The cache can be discarded at any time, so it is important that the primary copy of the data be kept somewhere else.
Due to the limited size of these faster memory tiers, we need an algorithm to decide which data to keep in the fast memory to increase the speed with which we can accomplish work. The most common algorithm for such a cache is called LRU (Least Recently Used). In this scheme, we keep the items sorted by the last time we used them. When a new item is added to the cache, it is inserted at the top of the list. If the cache is full, we remove items from the bottom of the list, the items used the longest ago (and least likely to be used again soon). If we access an item that is already in the cache, known as a “cache hit”, then we move that item back to the top of the list, so that we avoid removing it to make room for other items.
This algorithm is simple to implement and works quite well in many cases. However, there are certain common operations, such as taking backups, that make an LRU cache perform very poorly. When taking a backup of a system, the system scans every file to determine what has changed and therefore needs to be copied to the backup. By its very nature, this backup operation reads almost every file on the system, meaning the cache will rarely produce any hits, and all of the effort expended by the algorithm will be to add new data that will only be read once, and then removing that data from the cache a short time later to add different data that will also not be read a second time.
There is another algorithm that offers “scan resistance” to combat this drop in effectiveness from operations that read a lot of files, called MRU (Most Frequently Used). In this algorithm, instead of using the recency of data access to score which objects should remain in the cache, the scoring is based on how often the data is accessed. If you have read a certain critical data file 100 times, chances are you will read it again in the near future. There are of course downsides to this algorithm as well, if a file that was being used frequently is no longer used, maybe because it was rotated, or the workload changed, then it may take some other file that is now being used consistently a long time to dislodge this previously frequently used file from the cache.
The ARC algorithm
In 2003 IBM researchers Nimrod Megiddo and Dharmendra S. Modha published “Outperforming LRU with an Adaptive Replacement Cache Algorithm." It describes a new algorithm that combines the best of both a LRU and MFU cache with some additions that further enhance the algorithm.
The ARC, as implemented in ZFS, starts with the target size of the cache (represented by the variable C) split evenly (the split is represented by the variable P) between Most Recently Used (MRU) and Most Frequently Used (MFU).
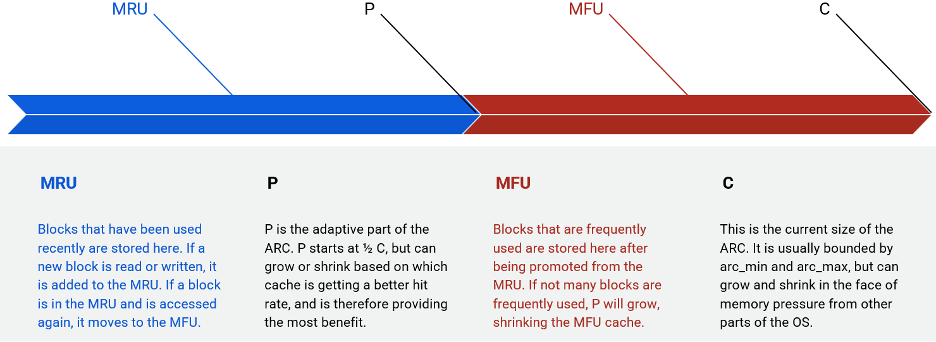
When an object is requested and is already resident in the MRU or MFU: this is a “cache hit”, data is in the fast cache and does not need to be retrieved from slow storage, good job! The object has now been accessed frequently, which results in it moving to the MFU if not already there. If it is already in the MFU, its counter is incremented to show that it continues to be used frequently. When a page is requested and it is not resident in either cache, this is a miss, better luck next time!
In addition to the cache itself, the ARC also maintains some additional statistics, called the “ghost lists”, one each for the MRU and MFU. When an object is evicted from the cache to make room for a new object, while the data is discarded from the cache, the index entry for the object is moved to the respective ghost list.
When an object is requested and it is on one of the ghost lists, this means “If only that particular cache had been a little bit bigger, we wouldn’t have evicted this object and this would have been a hit”. We were so close...
If the hit is on the MRU ghost list, the value of P is increased, making the MRU larger, and the MFU smaller. If the hit is on the MFU ghost list, the size of P is reduced, providing more MFU and less MRU. The value of P is constantly changing to move towards the best mix of the MRU and MFU algorithms as the workload changes. This is the “Adaptive” feature of the ARC.
Data vs Metadata
Not all data is the same, or in the cache of ZFS, not all data is data, but rather metadata, the ZFS indirect blocks, block pointers, and other machinery that makes ZFS work. The latency of this metadata is critical to the performance of all I/O, as ZFS needs to read the indirect blocks to locate or update the data you are trying to read or write.
In versions of ZFS prior to 2.2.0, the amount of metadata cached in the ARC was limited to a default of 75% of the size of the ARC. Additional tunables allow the administrator to adjust the eviction policy to favor data or metadata. However, this requires the administrator to have a detailed understanding of the workload and the potential impact of changing these settings. While ZFS split the metadata across MRU and MFU, it did not adapt to the changing needs of the application or users.
With the OpenZFS 2.2.0 release, these tunables were replaced, and instead, the ARC algorithm was employed a second time. In addition to adapting to whichever mix of MRU and MFU provides the best performance, it now also adapts to the mix of data and metadata that yields the best outcome. If the workload changes and becomes more metadata-heavy, the ARC will adapt and start preferring to cache more metadata. By continuing to use a mix of MRU and MFU, the data and metadata retain the property of being resistant to “scans” and other periodic tasks that would diminish the effectiveness of a normal LRU cache. With this change, ZFS requires less tuning and provides better outcomes by automatically reacting to changes in workload and adapting its caching algorithm to whatever mix of recency, frequency, metadata, and data will provide the best outcome for the users and applications.
Conclusion
We hope this brief overview of memory hierarchies and how traditional caching works helps you to understand the ZFS’s Adaptive Replacement Cache (ARC) and how its recent enhancements make it even more powerful. The ARC algorithm is beautiful in both its simplicity and efficiency, and it is interesting to see how it can be applied recursively to provide even more benefit. If you want to keep reading, learn about the L2ARC, the next level in the caching hierarchy.